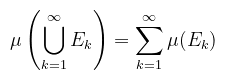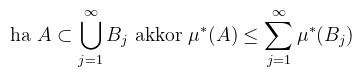|
Rendíthetetlenül tovább haladva a physically based rendering már kitaposott, helyenként mocsaras, néhol kövekkel teleszórt ösvényén (melyen rendkívül egyszerű elzanyálni), elérkezünk a szakmai berkekben state of the art-nak nevezett megjelenítési módszerekhez, melyek közül a path tracing, illetve a hozzá kapcsolódó fejlettebb technikák kombájnként tarolják le az előttük felmerülő problémák gyanútlan mezejét (és persze a programozó haját is).
Tartalomjegyzék
Mivel sok új fogalom lesz bevezetve, a használt matematikai szimbólumok jelentését ismét kigyűjtöttem. Feltételezem viszont, hogy az olvasó tisztában van a Cantor-féle halmazelmélettel és az alapvető differenciál- és integrálszámítási fogalmakkal.
Amikor olyanokat mondok, hogy "jelöljük", "nevezzük", stb., akkor az alatt a magyar/orosz notációt értem, amitől pl. az angol/német eltér. A jelölések lehetnek kontextusfüggőek, ilyenkor máshogy vannak formázva (dőlt, félkövér, stb.). Kötőszó gyanánt helyenként a latin id est ("azaz") és exempli gratia ("például") kifejezéseket használom, hogy ne unatkozzak. Eddig, amikor integrálásról volt szó, akkor vagy mellőztem a konkrét definíciót, vagy visszavezettem Riemann-integrálra. Amit erről tudni kell, hogy csak véges és zárt intervallumokon van értelmezve (ill. az integrálandó függvény ezen intervallumon korlátos kell legyen). Az egyik kiterjesztése az ún. improprius Riemann integrál, ami az előbbitől eltérő esetekben az integrál határértékét veszi. Egy másik problémája, hogy függvénysorozatok esetében a határérték csak bizonyos feltételek mellett hozható ki az integráljel alól (az ún. monoton konvergencia tétel nem teljesül).
Az ℝn nyílt halmazai (i.e. nem tartalmazzák a határmenti pontokat) által generált σ-algebra (jelölésben ℬ(ℝn)) elemeit az ℝn Borel-mérhető halmazainak hívjuk. Definíció (mérték): legyen Σ az X halmaz feletti σ-algebra, ekkor a μ : Σ → [0, ∞] függvényt mértéknek nevezzük, ha
Klasszikus példa a számláló mérték, ami az A ∈ Σ halmazokhoz hozzárendeli az elemszámukat. Az (X, Σ, μ) hármast mértéktérnek nevezzük. Ha minden nullmértékű halmaz összes részhalmaza mérhető, akkor mértéktér illetve a mérték teljes. Amennyiben μ(X) = 1, akkor a mértékteret valószínűségi mezőnek, Σ elemeit eseményeknek, μ-t pedig valószínűségnek hívjuk (ez később is meg lesz említve). Definíció (külső mérték): legyen 𝒫(X) valamilyen X halmaz hatványhalmaza, ekkor a μ* : 𝒫(X) → [0, ∞] függvényt külső mértéknek nevezzük, ha
Definíció (μ*-mérhetőség): legyen μ* külső mérték az X halmazon, ekkor az E ⊂ X halmaz μ*-mérhető, ha 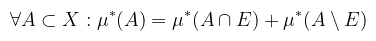
Értsük ezt úgy, hogy ha veszek bármilyen A halmazt, és két részre vágom az E halmazzal ("kimaszkolom"), akkor az nem változtatja meg az A halmaz külső mértékét (ld. Carathéodory-kritérium), i.e. megegyezik a két rész külső mértékének összegével. Tétel (külső mérték konstruálása): legyen ℋ ⊂ 𝒫(X) halmazrendszer, ν : ℋ → [0, ∞] függvény, ν(∅) = 0, E ⊂ X és 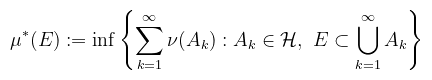
ekkor μ* külső mérték és a ν-höz tartozó külső mértéknek nevezzük. Ez azt jelenti, hogy legenerálom az összes lehetséges "túllógó" lefedést és veszem ezeknek a legnagyobb alsó korlátját. Intuitívan tehát valóban külső mértéket készítettem. Vegyük észre, hogy a lefedést alkotó halmazokra nincs kikötve sem az, hogy véges sokan vannak, sem az, hogy mérhetőek. Továbbá, E-re nincs kikötve, hogy korlátos (és így körvonalazódik, hogy a majd ebből képzett integrálfogalom általánosabb lesz a Riemann-integrálnál). Tétel (mérték konstruálása): legyen μ* külső mérték az X halmazon, Σ az X μ*-mérhető részhalmazainak halmazrendszere és μ a μ*-nak a Σ-ra vett megszorítása. Ekkor (X, Σ, μ) teljes mértéktér. Ha X a valós számok halmaza (ℝ) és ν-t a zárt, nyílt vagy félig nyílt intervallumok hosszaként definiáljuk, akkor az ehhez tartozó külső mérték a Lebesgue külső mérték (λ*), a λ*-mérhető intervallumok halmaza a Lebesgue σ-algebra (ℒ), melynek elemei a Lebesgue-mérhető halmazok, és λ*-nak az ℒ-re vett megszorítása a Lebesgue-mérték (λ). Az ℝn-re való megfogalmazás teljesen hasonló, az intervallum szót téglára (intervallumok Descartes-szorzata), a hosszt pedig a megfelelő analóg fogalomra cserélve (intervallumok hosszainak szorzata). A jelölések ilyenkor ℒn illetve λn (n-dimenziós Lebesgue-mérték). Konyhanyelven λ-t hossznak, λ2-et területnek, λ3-at térfogatnak nevezzük. Térfogatból lehet levest is főzni, ami nem finom, de azért sok. Definíció (μ-majdnem mindenütt): legyen (X, Σ, μ) mértéktér és ℓ : X → { igaz, hamis } logikai függvény. Legyen H ⊂ X az a halmaz, ahol ℓ értelmezett és az értéke igaz. Azt mondjuk, hogy ℓ μ-majdnem mindenütt teljesül X-en, ha X/H nullmértékű. Tehát valamilyen tulajdonságra akkor mondjuk, hogy μ-majdnem mindenütt (röviden μ-m. m.) teljesül, ha egy nullmértékű halmaz kivételével mindenhol teljesül. (megj.: az ilyen szavakat, hogy "mindenhol", részhalmazokra is lehet érteni; a fenti egy egyszerűsített definíció) Definíció (mérhető függvény): legyenek (X, Σ) és (Y, T) mérhető terek. Egy f : X → Y függvényt mérhetőnek nevezünk, ha minden E ∈ T halmaz f-szerinti ősképe eleme Σ-nak. Formálisan: 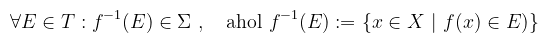
Ha (Y, T) = (ℝn, ℬ(ℝn)) és μ egy Σ-n értelmezett mérték, akkor a függvényt μ-mérhetőnek nevezzük (i.e. minden Borel-mérhető halmaz ősképe mérhető). Speciel ha (X, Σ) = (ℝ, ℒ) és (Y, T) = (ℝ, ℬ(ℝ)), illetve μ = λ, akkor az f : ℝ → ℝ függvény Lebesgue-mérhető. Ami még megemlítendő, hogy a valószínűségi változók mérhető függvények a valószínűségi mezőkön. Definíció (integrál): maga a fogalom továbbra is hasonlót jelent, mint eddig: valamilyen függvény alatti "terület", tehát egy valós szám (vagy végtelen). A függvény viszont most tetszőleges halmazon van értelmezve, amire nem tudunk úgy felosztást készíteni, mint a Riemann-integrál esetében. A felosztást ezért az értékkékészletre csináljuk meg és a függvény segítségével állítjuk elő a közelítést. Legyen (X, Σ, μ) mértéktér, f : X → [0, ∞] μ-mérhető, és definiáljuk az alábbi halmazrendszert: 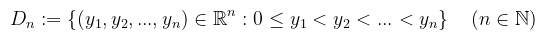
ami tehát a nemnegatív valós számok összes lehetséges n-elemű felosztásainak halmazrendszere. Egy y = (y1, y2, ..., yn) ∈ Dn-re legyenek 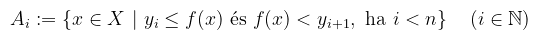
Ez a definíció rendkívül könnyen félreértelmezhető, úgyhogy kicsit részleteném, hogy mit jelent. Adott egy y felosztás a függvény értékkészletén, amihez felosztást keresek az értelmezési tartományban: ezt a felosztást alkotják az Ai halmazok. A félreértés abból adódik, hogy például az angol wikipédia ezt úgy mutatja be, mintha "vízszintes gerendákkal" próbálnám közelíteni a függvény alatti területet (egyébként lehet), de ez ebben a felírásban nem igaz! Az Ai halmazok tehát X-nek egy y-hoz tartozó felosztását adják meg, és a függvény alatti "függőleges oszlopok alapjai". Egy adott ilyen Ai "alapnak" a mérete μ(Ai). Ekkor az f függvény y-hoz tartozó integrálközelítő összege 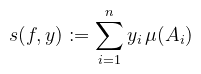
i.e. az "oszlopok" méreteinek összege. Az f függvény integrálja pedig 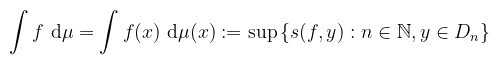
Vagyis az összes lehetséges felosztásból képzett integrálközelítő összeg legkisebb felső korlátja. Még nem vagyunk készen, hiszen a definíció elején feltettük, hogy a függvény nemnegatív. Tetszőleges f : X → ℝ μ-mérhető függvény integrálját úgy képezzük, hogy kettéválasztjuk a pozitív és negatív részére: 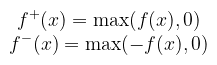
Arra kell ügyelni, hogy a két rész integrálja közül legalább az egyik véges legyen, ekkor azt mondjuk, hogy az f-nek létezik integrálja, és azt a két rész integráljának különbségeként kapjuk meg. Definíció (mérhető halmazon vett integrál): legyen (X, Σ, μ) mértéktér, f : X → ℝ és E ∈ Σ. Azt mondjuk, hogy az f-nek létezik integrálja az E halmazon, ha a megadott f*-nak létezik integrálja, ekkor 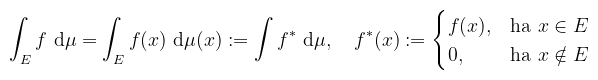
Ha ennek az értéke valós (véges), akkor f-et integrálhatónak nevezzük E felett. Különbség van tehát aközött, hogy egy függvénynek létezik-e integrálja és hogy integrálható-e. Utóbbinál feltétel, hogy az integrál véges legyen. Amennyiben μ az n-dimenziós Lebesgue-mérték (λn), akkor az integrált Lebesgue-integrálnak nevezzük (de a továbbiakhoz n = 1-et feltételezek). Néhány megjegyzés, biz. nélkül:
Tétel (Lebesgue-kritérium): az f : [a, b] → ℝ (a, b ∈ ℝ, a < b) korlátos függvény pontosan akkor Riemann-integrálható, ha λ-majdnem mindenütt folytonos [a, b]-n. Ilyenkor persze alkalmazhatóak a Riemann-integrálnál tanult tételek (pl. Newton-Leibniz). Ne felejtsük el azonban, hogy Lebesgue-értelemben nem definiáltunk olyan fogalmat, hogy primitívfüggvény (i.e. határozatlan integrál)! Amennyiben mégis használom, akkor implicit feltételezem, hogy a Lebesgue-kritérium teljesül. Mielőtt rátérnék a valszámra, ebben a rövid bekezdésben ismertetek egy fontos tételt, ami a különféle mértékek közötti átváltást teszi lehetővé. Kiemelt szerepe van a (valószínűségi) sűrűségek közötti konverziónál.
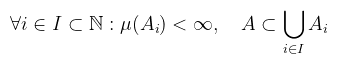
Tehát az A halmaz lefedhető véges mértékű Ai halmazok úniójával. Ha maga az X halmaz σ-véges, akkor a mértékteret és a mértéket is σ-végesnek nevezzük. Definíció (mérték abszolút folytonossága): legyen ν és μ két mérték ugyanazon az (X, Σ) mérhető téren, ekkor ν abszolút folytonos μ-re nézve (ν ≪ μ), ha 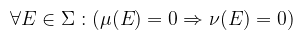
Az implikáció tulajdonságai miatt a jelölés nem részbenrendezést (≤) jelent: a reflexivitás és a tranzitivitás teljesül, az antiszimmetria viszont nem (de a szimmetria sem). Emiatt két mértéket akkor tekintünk ekvivalensnek, ha kölcsönösen abszolút folytonosak (i.e. ν ≪ μ és μ ≪ ν). Úgy is meg lehet fogalmazni, hogy ν abszolút folytonos μ-re nézve, ha minden μ-nullmértékű halmaz ν-nullmértékű is (de fordítva nem feltétlenül!). Tétel (Radon-Nikodym): legyen ν és μ két σ-véges mérték az (X, Σ) mérhető téren. Ha ν ≪ μ, akkor létezik f : X → [0, ∞) μ-mérhető függvény, amelyre 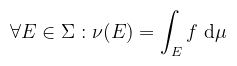
Ekkor a dν/dμ := f függvényt a ν-nek μ-re vonatkozó Radon-Nikodym-deriváltjának nevezzük, és ez a függvény μ-majdnem mindenütt egyértelmű (tehát ha van egy hasonló g függvény is, akkor f = g μ-m. m.). Ez elsősorban a valószínűségszámításban játszik szerepet (f ún. sűrűségfüggvény), de amint látni fogjuk, tulajdonképpen végig Radon-Nikodym-deriváltakkal dolgozunk majd, csak fölösleges mindenhol felemlegetni. Konyhanyelven a valszámnak az a megfigyelés az alapja, hogy egy véletlenszerű eseményt (pl. kockadobás) elég sokszor megismételve, az esemény relatív gyakorisága egy konstanshoz közelít, amit az esemény valószínűségének nevezünk. Például egy szabályos dobókocka esetén annak az esélye, hogy hatost dobok 1/6. A kockadobáshoz annak kimenetelét hozzárendelő függvény egy (diszkrét) valószínűségi változó.
A fent tanultak segítségével fogalmazzuk ezt meg általánosabban.
akkor ξ-t valószínűségi változónak nevezzük. Fent említettem, hogy ez mérhető függvény, konkrétan az a spec. eset, amikor T = { (-∞, x) : x ∈ ℝ }, amiről belátható, hogy (Borel) σ-algebra. Pongyolán mondható az, hogy a v.v. a lehetséges kimenetelekhez olyan értékeket rendel, amiknek a valószínűsége "értelmes" (i.e. jól definiált az integrálás szempontjából). Valószínűségi változóra alkalmazva valamilyen mérhető f függvényt, szintén v.v.-t kapunk. A gyakorlatban eltekintünk attól, hogy függvény és csak valamilyen esemény kimeneteléhez rendelt értékként kezeljük. Szemléltető példa (folytonos v.v.-ra) mondjuk a lehetséges hőmérsékletek egy adott napon. Több valószínűségi változót függetlennek nevezünk, ha a definícióban szereplő halmazaik (mint események) függetlenek, i.e. a metszetük valószínűsége a valószínűségeik szorzata. Definíció (eloszlásfüggvény): a ξ valószínűségi változó eloszlásfüggvényének az alábbi P : ℝ → [0, 1] függvényt nevezzük: 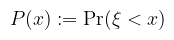
Bár a ξ < x kifejezés a fentiek értelmében egy halmazt jelöl (és emiatt bizonyos irodalmak kapcsos zárójelbe teszik), ettől kényelmi szempontból szintén eltekintünk. Az eloszlásfüggvény így azt mondja meg, hogy mekkora a valószínűsége annak, hogy a v.v. az x értéknél kisebb. (megj.: az angol szakirodalmak megengedik a ≤-t is, ez annyit változtat, hogy a függvény jobbról lesz folytonos bal helyett) Definíció (sűrűségfüggvény): a ξ valószínűségi változót abszolút folytonosnak nevezzük, ha létezik olyan p : ℝ → [0, ∞) Lebesgue-integrálható függvény, hogy 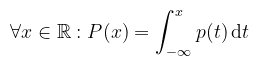
ekkor p-t a ξ sűrűségfüggvényének (probability density function) nevezzük. Egy fontos dologra felhívnám a figyelmet: a sűrűségfüggvény azt mondja meg, hogy a folytonos v.v. milyen relatív valószínűséggel vesz fel egy adott értéket (azért relatív, mert annak a valsége, hogy egy konkrét értéket vesz fel nulla). A gyakorlatban ez inkább úgy mutatkozik meg, hogy mennyire valószínű, hogy a v.v. egy adott intervallumba esik. Maradva a hőmérsékletes példánál: annak a valószínűsége, hogy pontosan 16 fok van odakint nulla, de azt meg lehet mondani, hogy mekkora eséllyel esik 15.9 és 16.1 közé. Erre vonatkozik a következő állítás. Tétel (sűrűségfüggvény tulajdonságai): ha ξ abszolút folytonos valószínűségi változó, akkor minden a, b ∈ ℝ, a < b esetén: 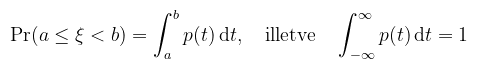
Röviden tehát, ha létezik a v.v.-nak sűrűségfüggvénye, akkor annak a valószínűsége, hogy egy adott intervallumba esik, a sűrűségfüggvény alatti terület azon az intervallumon. Máshogy megfogalmazva a sűrűségfüggvény az eloszlásfüggvénynek a Lebesgue-mértékre vonatkozó Radon-Nikodym-deriváltja. Definíció (többdimenziós eloszlás): a ξ = (ξ1, ..., ξn) valószínűségi vektorváltozó közös eloszlásfüggvénye (joint cumulative distribution function) a P : ℝn → [0, 1] függvény: 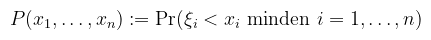
közös sűrűségfüggvénye (joint density function): 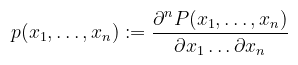
úgy, hogy minden D ⊂ ℝn Lebesgue-mérhető halmazra: 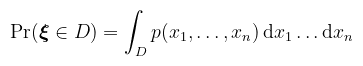
A fogalom kulcsfontosságú szerepet fog játszani a későbbiekben, ugyanis az ún. importance sampling során sűrűségfüggvényeket fogunk keresni, amikből integrálással meghatározva az eloszlásfüggvényt, mintákat (lehetséges kimeneteleket) lehet generálni (például irányokat egy félgömbön belül). A fogalmak tovább általánosíthatóak, ahol is az eloszlásfüggvény ún. valószínűségi mérték valamilyen μ alapmértékre nézve, ekkor a sűrűségfüggvény szimplán a μ-re vonatkozó Radon-Nikodym-derivált. Ezt külön nem írom le, mert ahogy látni fogjuk, a használt fogalmakhoz (felszín, térszög) elegendő a fenti definíciókat tudni, csak a formulák lesznek rövidebbek. Definíció (várható érték): legyen (Ω, ℱ, Pr) valószínűségi mező és ξ egy ezen értelmezett valószínűségi változó. A ξ várható értékének nevezzük az 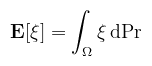
integrált, amennyiben az létezik és véges. Talán könnyebb megérteni diszkrét esetben, ahol a várható érték a érték-valószínűség szorzatoknak az összege. Megint a kockadobást felhozva példaként, az értékek halmaza { 1, 2, 3, 4, 5, 6 }, egy konkrét érték dobásának valsége 1/6, tehát akkor a kockadobás várható értéke 1/6 · (1 + 2 + 3 + 4 + 5 + 6) = 3.5 A definícióban szereplő folytonos v.v.-ra ez analóg módon egy integrál. De lehet ennél jobbat is mondani: Tétel (a.f. v.v. várható értéke): amennyiben ξ abszolút folytonos v.v. (létezik sűrűségfüggvénye), akkor 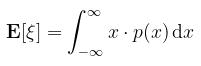
Ez már jobban hasonlít a diszkrét esetre (persze nyilván még mindig integrál). Tudnánk-e valami hasonlót mondani függvényekre (ami integrálközelítésnél segít majd)? Tétel (az eszméletlen statisztikus törvénye): legyen g a ξ valószínűségi változóra értelmezett mérhető függvény, ekkor 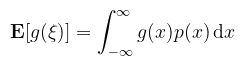
(megj.: ez valószínűségi vektorváltozóra is igaz, ahol p a közös sűrűségfüggvény és többszörösen kell integrálni) Ezek szerint egy tetszőleges mérhető függvény integrálja tekinthető a függvény várható értékének, amennyiben ismerünk hozzá sűrűségfüggvényt. Ehhez kapcsolódik a várható értéknek egy fontos tulajdonsága: Tétel (a várható érték lineáris): legyenek ξ1, …, ξn valószínűségi változók és α1, …, αn ∈ ℝ konstantsok, ekkor 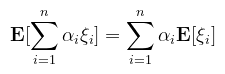
A várható érték ezen tulajdonságai miatt "működik" a Monte Carlo közelítés; a vonatkozó bekezdésben rakom majd ezeket össze. Definíció (szórásnégyzet): legyen ξ véges várható értékű valószínűségi változó, ekkor ξ szórásnégyzete (variance) 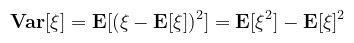
Az egyenlőség a várható érték linearitásából levezethető. A szórásnégyzet pongyolán azt mondja meg, hogy a v.v. értékei mennyire térnek el a várható értéktől. Megint kockadobásra, E[ξ2] = 1/6 · (1 + 4 + 9 + 16 + 25 + 36) ≈ 15.16, amiből E[ξ2] - E[ξ]2 ≈ 2.91 A szórásnégyzet négyzetgyökét nevezzük szórásnak (standard deviation). A fogalom nem hat újdonságként, hiszen a variance shadow mapping keretében már volt róla szó. Ugyanott meg lett említve, hogy az átlag (μ) a v.v. első, a szórásnégyzet (σ2) pedig a második ún. (centrális) momentuma (ne keverjük a korábbi szimbólumokkal). A variancia jellemzi majd a Monte Carlo közelítés pontosságát: a magas szórásnégyzetű helyeken ún. firefly-ok (fehér pöttyök) jelentkeznek a képen. Az elsődleges cél ezeknek az eltüntetése lesz, különféle mintavételezési stratégiákkal. Tétel (a szórásnégyzet tulajdonságai): legyenek ξ1, …, ξn független valószínűségi változók és α1, …, αn ∈ ℝ konstantsok, ekkor 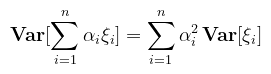
Vigyázat, a függetlenség fontos ennek teljesüléséhez (míg a várható értéknél ez nincs kikötve). Definíció (peremsűrűség): legyen ξ = (ξ1, ..., ξn) valószínűségi vektorváltozó a p(x1, ..., xn) közös sűrűségfüggvénnyel, ekkor a ξi valószínűségi változókra külön definiálhatók az ún. peremsűrűségek (marginal density function): 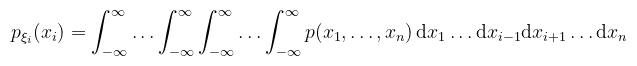
Bár a formula ijesztőnek tűnik, mindössze annyit mond, hogy az i-edik változó szerint nem integrálunk. A gyakorlatban a kétdimenziós esettel fogok csak foglalkozni, tehát ξ1 és ξ2 valségi változók a p(x, y) közös sűrűségfüggvénnyel, ekkor a peremsűrűségek: 
A peremeloszlásfüggvények pedig: 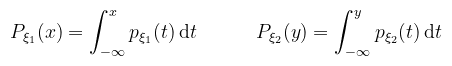
Ez a kétdimenziós inverziós módszernél (később) kap majd szerepet, ahol a félgömb, mint függvény paramétereit v.v.-nak tekintve a peremeloszlásfüggvények inverzéből mintavételezési irányokat állítunk elő. Ehhez szükséges még egy fogalom: Definíció (feltételes sűrűségfüggvény): legyenek ξ1 és ξ2 valségi változók a p(x, y) közös sűrűségfüggvénnyel, ekkor ξ2 feltételes sűrűségfüggvénye amennyiben ξ1 már ismert: 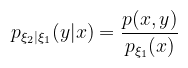
A gyakran emlegetett koszinusz mintavételezés irányait ezen fogalmak segítségével lehet levezetni (ld. lent). Különösen érdekes lesz, amikor bonyolultabb BSDF-ekhez kell mintavételezési stratégiát konstruálni (pl. fénytöréshez). Először is egy kis motiváció, hogy miért nem jók a klasszikus integrálközelítő módszerek (trapéz szabály, Simpson-módszer, stb.). Ezek ún. hibája (mennyire tér el az integráltól) a felosztás finomságától függ, tehát úgy lehet pontosabb közelítést kapni, ha növeljük a részintervallumok számát (N). Magasabb dimenziókban viszont ez az érték hatványozódik az analóg fogalmakra: 2D-ben már N2 minta kell, 3D-ben N3, stb. Amellett, hogy kiszámolni sem egyszerű, a hiba is növekszik.
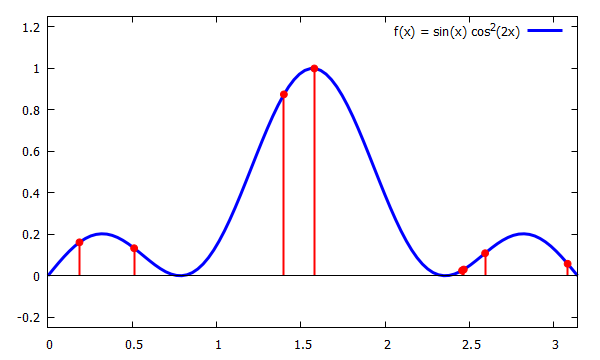
Alapvető különbség, hogy nem érdekel minket, hogy mekkora a távolság a minták (a diagramon piros vonalak) között, csak az érdekel, hogy átlagban igazodjon a választott pdf-hez (pl. egyenletes eloszlás esetén 1/N, ahol N a minták száma). Ahogy fent megbeszéltük, a diagramon szereplő f függvény (mint v.v.) várható értéke az alábbi integrál: 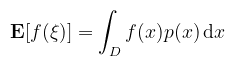
(megj.: nem muszáj végtelenig integrálni, ha nem az a kérdés) Na oké, de nekünk az f függvény integrálja kellene! Az említett naiv megoldás az, hogy pdf-nek egy konstansot választunk, konkrétan p(x) := 1 / λ(D) és ez felel meg az egyenletes eloszlásnak, ami a folytonos értelemben vett "átlag" fogalom. Az eredetileg Horvitz-Thompson közelítőnek nevezett módszer erre azt mondja, hogy ha úgyis (nem naiv esetben súlyozott) átlagot számolunk, akkor az integrálközelítő legyen az 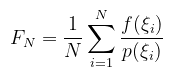
valószínűségi változó, amiről a várható érték tulajdonságai alapján belátható, hogy valóban a függvény integrálját állítja elő: 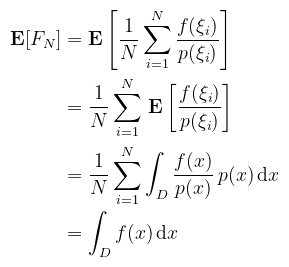
A közelítés érvényességéhez követelmény, hogy a pdf pozitív legyen (nincs negatív valószínűség!), a D tartományon 1-hez integráljon, és ne legyen nulla ott, ahol f nemnulla (ez a GPU implementációban okoz majd némi problémát). Tétel (a Monte Carlo közelítés hibája): kihasználva, hogy a módszer független v.v.-kkal dolgozik, a szórásnégyzetre az alábbi mondható: 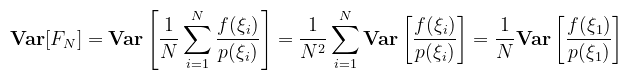
Mégegyszer, ez azért igaz, mert ξi-k függetlenek és ugyanabból az eloszlásból valók. Triviális tehát, hogy elég csak az egyik v.v. szórásnégyzetét kiszámolni (legyen csak simán ξ). Jelöljük I-vel az f integrálját D-n, és alkalmazzuk a tanult képleteket: 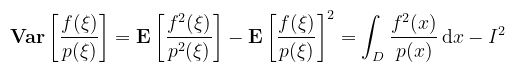
A két egyenletet összerakva azt kapjuk, hogy a szórás (a.k.a. root-mean-square error): 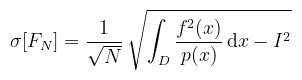
Amiből az látható, hogy a közelítés (átlagos) hibája a minták számának inverz gyökével konvergál nullához. Ez azt jelenti, hogy ha felezni akarom a hibát, akkor négyszer annyi mintát kell vennem. Ez elsőre nem hangzik túl jól, de emlékezzünk, hogy a dimenziók számától független! A path tracing pedig, ha az összes lehetséges útvonalak terét tekintjük, valójában végtelen dimenziós! Egy további erősség a pdf megválaszthatósága (ez a multiple importance sampling-nál fog kibontakozni). Az alábbi példákban D = [0, π] az integrálás tartománya, az f függvény pedig ami a diagramon szerepel. Példa (naiv Monte Carlo): vagyis egyenletes eloszlás, azaz p(x) = 1 / π és ez teljesíti is a sűrűségfüggvény feltételeit. A tanultak alapján az eloszlásfüggvény (CDF) és annak inverze kiszámolható: 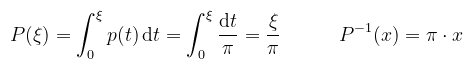
Ez az ún. inverziós módszer, ami folytonos v.v.-k egy mintavételezési technikája: a [0, 1]-beli egyenletes eloszlású v.v.-t áttranszformálja egy másik (itt most a [0, π]-beli szintén egyenletes) eloszlásba. Az alábbi C++ kód demonstrálja a naiv Monte Carlo közelítést: CODE
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<double> dis;
int N = 16384;
double F_N = 0;
for (int k = 0; k < N; ++k) {
double x_k = dis(gen);
double xi_k = M_PI * x_k;
// f(ξk) / p(ξk)
double costerm = cos(2.0 * xi_k);
F_N += sin(xi_k) * costerm * costerm * M_PI;
}
F_N /= N;
printf("%.6f\n", F_N);
A várt eredmény 0.933333333333, de világos, hogy a véletlenszerű természetből adódóan hol alul- hol felülbecsüli. A szórás kiszámolásához egy elég ronda integrált kellene megoldani (parciális integrálás, u-helyettesítés, stb.), szerencsére vannak programok amik elvégzik ezt helyettünk. A szórás ismeretében (~0.0077) lehet írni egy egyszerű programot, ami a fenti kódot lefuttatja párszor és megmondja, hogy hibahatáron belül van-e az érték (csak az érdekes, hogy átlagosan belül legyen). Példa (importance sampling): ahogy említettem az egyenletes eloszlással az a probléma, hogy fölöslegesen vesz mintákat olyan helyekről, amik keveset tesznek hozzá az integrálhoz. A cél mindig az, hogy a pdf-et úgy válasszuk meg, hogy az integrálandó függvényből lehetőleg konstans legyen (ekkor a szórás ugyanis nulla). Nyilván ez általában nem tehető meg, de bizonyos domináns részeit el tudjuk tüntetni. Persze azt is érdemes szem előtt tartani, hogy melyik résznek tudjuk analitikusan kiszámolni az integrálját. Sőt, voltam olyan idióta, hogy cos2(2x)-re kezdtem el kiszámolni, ami szép és jó, csak a CDF inverze nem fejezhető ki elemi függvényekkel (x + sin(x) alakú transzcendens függvény, túlmutat az algebrán). Marad tehát sin(x), amire gondolkozás nélkül rávágható, hogy p(x) = sin(x) / 2, amiből az eloszlásfüggvény és az inverze: 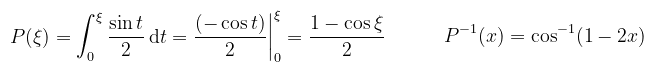
Ami alapján a kód: CODE
int N = 16384;
double F_N = 0;
for (int k = 0; k < N; ++k) {
double x_k = dis(gen);
double xi_k = acos(1.0 - 2.0 * x_k);
// f(ξk) / p(ξk)
double costerm = cos(2.0 * xi_k);
F_N += costerm * costerm * 2.0;
}
F_N /= N;
printf("%.6f\n", F_N);
Megint segítségül hívva a Desmos-t, látszik, hogy csökkent a szórás (~0.0054). Azt még ki lehet számolni, hogy ha a cos2(2x) tagot ejtenénk ki, akkor mennyi lenne (~0.0047). Az importance sampling lényege tehát, hogy az integrálandó függvénynek egy olyan részéből csináljunk pdf-et, amit tudunk analitikusan integrálni. Definíció (torzítás): a Monte Carlo integrálás célja, hogy valamilyen mennyiséget (quantity of interest, Q) közelítsen (jelen esetben Q az integrál értéke) valamilyen FN = FN(ξ1, ..., ξN) közelítővel (estimator). A közelítő torzításának (bias) nevezzük a 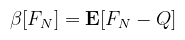
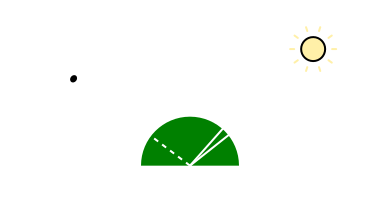
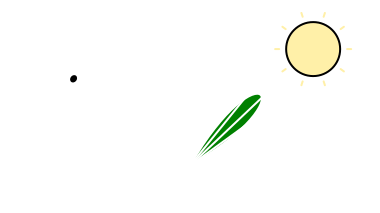
várható értéket. Amennyiben minden N-re a torzítás nulla, akkor a közelítő torzítatlan/elfogulatlan (unbiased). A fenti levezetésből látható, hogy a Monte Carlo közelítőre ez igaz (i.e. E[FN] = Q). Ezt azért említem meg, mert egy hibás implementáció könnyen elfogulttá teheti a módszert (pl. ha a v.v.-k nem függetlenek). Ugyanakkor vannak technikák, amik szándékosan bevezetnek torzítást (ún. kvázi-Monte Carlo módszerek) valamilyen kvázi-véletlenszerű sorozattal (low-discrepancy sequence). A cikk végén majd mondok erre néhány példát. A megjelenítés konkrét fogalmait egyelőre mellőzve, intuitívan menjünk végig a fényforrásokon, illetve a fény-felület interakción. Amikor ránézünk egy fényforrásra, akkor a "fényességét" tetszőleges irányból és távolságból ugyanolyan erősnek érzékeljük. Ami változik az az ún. térszög, ami alól látható (ha messzebb megyek, akkor kisebbnek tűnik).
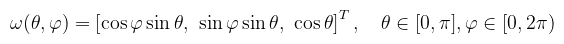
(megj.: a paraméterek sorrendje nem mindegy, én itt az ISO konvenciót használom) A differenciális térszöget a felületi integrál kapcsán értelmezem, mint azt a végtelenül kicsi felületdarabot, ami szerint az integrálás történik. Pongyolán a felületi integrál definícióját kihasználva valamilyen f teljesen érdektelen függvényre: 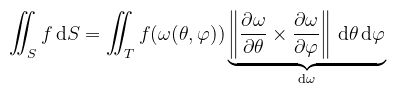
Ahol T most a [0, π] × [0, 2π] síkdarab. A parciális deriváltakat kiszámolva és Wolfram Alpha-ba bepötyögve, a dω-val jelölt értékre az alábbit kapjuk: 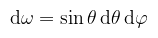
Vizuálisan is lehet értelmezni az egyenlőséget, mint a differenciális szögek által kimetszett négyszög területét, ami a négyszög két oldalának a szorzata. Azért nem így mutattam be, mert a felszín alatt (pun intented) ez nem annyira triviális. A segítségével viszont kiszámolható például az egységgömb felszíne: 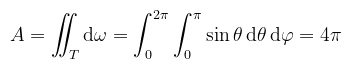
A térszög kapcsán megemlítendő még az egységgömb középpontjától r távolságra levő, n normálvektorú dA felületdarabkára vonatkozó képlet (a fent említett vetített terület/térszög): 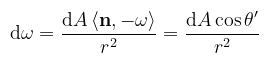
Ezt az azonosságot kihasználva az integrált lehet térszög helyett felszín szerint is venni (ez akkor segít, amikor a fényforrás "kicsi"). Visszakanyarodva a fény-felület interakcióhoz, az, hogy egy fényforrás mennyire tűnik fényesnek, nem mondja meg közvetlenül, hogy milyen erősséggel világít meg valamit. Könnyen demonstrálható egy lapos tárggyal, hogy ha messzebb viszem a fényforrástól és/vagy elforgatom, akkor sötétebbnek tűnik.
A továbbiakhoz még szükséges, hogy a (fél)gömbön (H) belül tudjunk irányokat választani. A Monte Carlo integrálás ugyanis 3D-ben is hasonló recept szerint működik, mint fent, viszont többdimenziós eloszlásokkal. Ehhez kicsit jobban meg kell érteni, hogy az inverziós módszer valójában mit csinál.
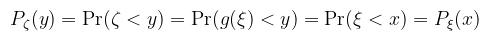
Amiből a sűrűségfüggvényekre a lánccszabály alkalmazásával az alábbi mondható: 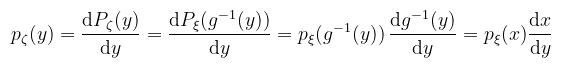
Amennyiben g monoton csökkenő, a jobb oldal negatív előjelű. Általánosan a következőképpen írható fel a egyenlőség: 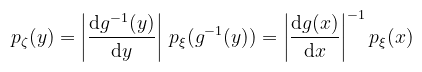
(megj.: ne keverjük, hogy a -1 hatvány mikor jelent inverzet és mikor reciprokot!) Tehát a sűrűségfüggvényt a g függvény deriváltjának abszolútértékével kell osztani (megfordítottam a hányadost). A levezetés kicsit részletesebben megtekinthető itt (csak annyiban tértem el, hogy egyből kihasználtam a bijektivitást). A gyakorlatban viszont a sűrűségfüggvények ismertek és a g függvényt (transzformációt) keressük. Az eloszlásfüggvényekre vonatkozó egyenlőségből könnyen látszik, hogy 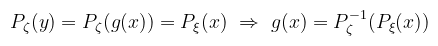
Ami az inverziós módszer általános megfogalmazása; a fenti példákban azt az esetet láttuk, amikor Pξ(x) az egyenletes eloszlás. Térjünk most át a többdimenziós eloszlásokra. A közös sűrűségfüggvényekre vonatkozó egyenlőség analóg módon értelmezhető valamilyen T bijektív leképezés Jacobi determinánsa segítségével, ahol most ζ = T(ξ) valószínűségi vektorváltozó: 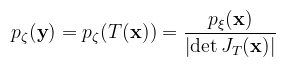
Példaként tekintsük a gömb fent megbeszélt paraméterezését, kiegészítve az r sugárral (i.e. T = r · ω): 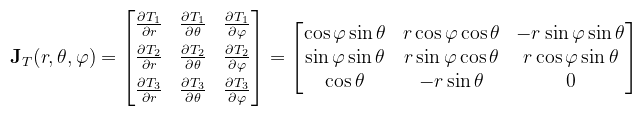
A paraméterek sorrendje még mindig nem mindegy, de most már legalább látjuk, hogy miért nem. A mátrix oszlopainak/sorainak cserélgetése ugyanis a determináns előjelét változtatja (illetve a koordinátarendszer irányítottságát). Mondhatnánk persze, hogy "most úgyis mindegy, mert abszolútértéket kell venni", de a negatív determináns egy kifordított felületet jelent, és pl. a normálvektorok szempontjából az már baromira nem mindegy. 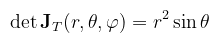
Tegye fel a kezét, aki meglepődött ezen (egyébként így hozható össze dω a Gauss-féle első alapmennyiséggel, ha esetleg vizsgakérdés lenne, mert hát miért is ne lenne az...). Megadható tehát a sűrűség konverziója Descartes-koordinátarendszerből gömbi koordinátarendszerbe: 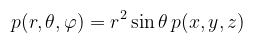
(megj.: az abszolútérték elhagyható, mivel θ ∈ [0, π], és a szinusz ott pozitív) Itt egy pillanatra álljunk meg, ugyanis az irodalmak kicsit zavarosan viszik tovább ezt az egyenlőséget. Csábító a gondolat, hogy mivel ω-t úgy definiáltuk, mint a gömbfelület pontjait, (x, y, z)-t egyszerűen lecserélhetnénk arra. Csakhogy itt sűrűségekről van szó, amit konkrét pontokra/irányokra nem használhatunk, viszont azoknak egy halmazára már igen. A helyes eljárás tehát az, hogy egy Ω térszögön vesszük az irányok sűrűségét, amit a p : ℝ3 → [0, ∞) sűrűségfüggvény ír le. Erre viszont a többdimenziós eloszlás definíciója szerint (itt most ω egyben valségi vektorváltozó is): 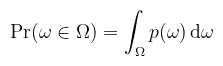
Így már mondhatjuk azt, hogy mivel egy környezetben vettük az irányokat, definiálható egy másik, p : ℝ2 → [0, ∞) közös sűrűségfüggvény θ-hoz és φ-hez, felhasználva a fenti felületi integrállal való definíciót: 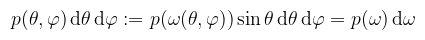
És alkalmazva a dω = sin θ dθ dφ egyenlőséget kapjuk az alábbi Kőbe Vésett Egyenlet™-et: 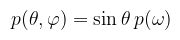
(megj.: gondolom mindenki látja, hogy az egyik p piros, a másik meg zöld) Ezzel minden készen áll ahhoz, hogy adott p(ω)-hoz az inverziós módszerrel meghatározzuk a θ és φ szögeket, azokból pedig az irányvektort valamilyen ξ1 és ξ2 továbbra is [0, 1]-beli egyenletes eloszlású valségi változókra. Példa (félgömb egyenletes mintavételezése): egyenletes eloszlásnál a pdf konstans, könnyen ki is lehet számolni (1-hez kell integráljon H-n), de intuitívan is meg tudjuk mondani, hogy p(ω) = 1/2π (merthogy a félgömb felszíne 2π). Úgy kezdődik a buli, hogy peremsűrűség valamelyik változóra (mondjuk θ) és feltételes sűrűség a másikra (az meg akkor φ): 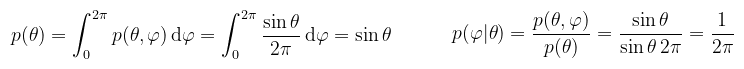
(megj.: azt látjuk, hogy θ és φ függetlenek, azaz valójában nem szükséges feltételes sűrűséget számolni) Jöhet a peremeloszlás és a feltételes eloszlás: 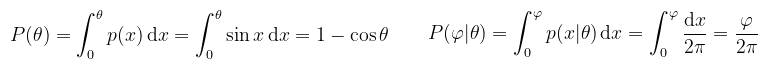
Invertálva ezeket megkaphatóak a szögek: 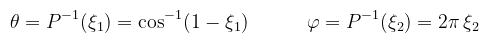
(megj.: ezért kellene alsó index; szintén vizsgához kapcsolódó tanács, hogy nemlétező fogalmakat inkább ne emlegessetek) Na és most megint álljunk meg, mert ész nélkül kódoltok. Tekerjünk vissza az egységgömb paraméterezéséhez, és a rendkívüli megvilágosodás után lássuk a kódot: CODE
vec4 UniformSampleHemisphere(float xi1, float xi2)
{
float phi = TWO_PI * xi2;
float costheta = xi1; // eml.: ξ1, ξ2 ∈ [0, 1]
float sintheta = sqrt(1.0 - costheta * costheta); // eml.: sin2 x + cos2 x = 1
vec4 w;
w.x = sintheta * cos(phi);
w.y = sintheta * sin(phi);
w.z = costheta;
w.w = 1.0 / TWO_PI; // pdf
return w;
}
Igen, namost ez a kanonikus bázisban van; értelemszerűen egy tetszőleges normálvektor (mint z-tengely) terébe át kell majd pakolni. Másik megoldás, hogy a bejövő/kimenő vektorokat transzformálod át ide. Én inkább az előbbi mellett döntöttem, mert csak (meg volt már írva). Nem felejtjük el, hogy a pdf-el mindig le kell osztani (szórakozottságból a kód visszaadja, hogy emlékeztessen), szóval ha ez élesben menne, akkor a közelítést szorozni kell 2π-vel. De. Példa (félgömb koszinusz mintavételezése): ez a következő bekezdésben nyer majd értelmet, most legyen elég annyi, hogy koszinusszal súlyozott függvényt szeretnénk integrálni. A félgömb aljánál az persze nulla, szóval azon a környéken nem, vagy csak kicsit visz közelebb az integrálhoz. Adódik tehát, hogy ki lehetne ejteni a pdf-el. Kis számolással ellenőrizhető, hogy a koszinusz integrálja a félgömbön π, tehát p(ω) = cos θ / π megfelel pdf-nek. Mivel láttuk, hogy θ és φ függetlenek, megspórolom a redundáns számolásokat: 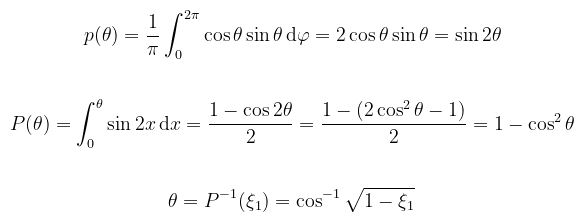
Oké bevallom, ehhez nekem is elő kellett kotornom a függvénytáblázatokat. Meglepő viszont, hogy a mintavételezés kódja csak a négyzetgyökben (és persze a pdf-ben) különbözik a fentitől: CODE
vec4 CosineSampleHemisphere(float xi1, float xi2)
{
float phi = TWO_PI * xi2;
float costheta = sqrt(xi1); // eml.: ξ1, ξ2 ∈ [0, 1]
float sintheta = sqrt(1.0 - costheta * costheta); // eml.: sin2 x + cos2 x = 1
vec4 w;
w.x = sintheta * cos(phi);
w.y = sintheta * sin(phi);
w.z = costheta;
w.w = costheta / PI; // pdf
return w;
}
Tényleg meglepő? A könyv részletesebben leírja, de valójában az egységkorong mintavételezését "nyújtottuk ki" egyenletesre, cserébe a félgömbön koszinusz eloszlású pontokat kapva (Malley-módszer). Ennek van egy olyan kellemetlen tulajdonsága, hogy az ún. rétegződést (stratification, értsd pl. multisampling) nem tartja meg. Olyan esetben ugyanez megtehető a Shirley-leképezéssel is (koncentrikus mintavételezés). Példa (kúp egyenletes mintavételezése): erre még szükség van; ilyenkor θ egy adott θmax nyitási szögig van értelmezve. Ez az első olyan példa, ahol nem nyilvánvaló, hogy mi a pdf, csak annyit tudunk, hogy konstans. 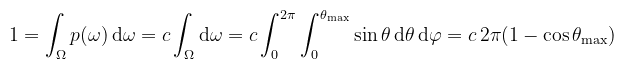
Dehogy bonyolult. Sőt, θ és φ még mindig függetlenek, szóval a közös sűrűség a peremsűrűségek szorzata (de), úgyhogy p(θ)-t fel sem írom külön. 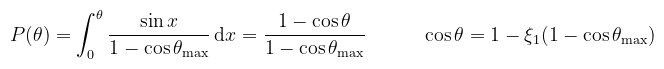
És azonnal írható is át kódba: CODE
vec4 UniformSampleCone(float xi1, float xi2, float costhetamax)
{
float phi = TWO_PI * xi2;
float costheta = (1.0 - xi1) + xi1 * costhetamax;
float sintheta = sqrt(1.0 - costheta * costheta); // eml.: sin2 x + cos2 x = 1
vec4 w;
w.x = sintheta * cos(phi);
w.y = sintheta * sin(phi);
w.z = costheta;
w.w = 1.0 / (TWO_PI * (1.0 - costhetamax)); // pdf
return w;
}
Persze ez is a kanonikus bázisban értendő (z-tengely körüli irányok). A könyv elég jól leírja a gyakorlati alkalmazást (gömb által kifeszített kúp mintavételezése), úgyhogy azt nem részletezem (a θmax nyitási szöget kell kiszámolni és az eredményt átforgatni a normálvektor terébe). Ha már átforgatás, egy tetszőleges n irányba felettébb egyszerű ezt megtenni (mindegyik itt említett példára): CODE
vec3 TransformToHemisphere(vec3 n, vec3 v)
{
vec3 up = ((abs(n.z) < 0.999) ? vec3(0, 0, 1) : vec3(1, 0, 0));
vec3 tangent = normalize(cross(up, n));
vec3 bitangent = cross(n, tangent);
return tangent * v.x + bitangent * v.y + n * v.z;
}
A kód n körül generál egy ortonormált bázist és átpakolja a v vektort oda. Ahogy mondtam, már meg volt írva, ezért használom (a másik lehetőséget akkor érdemes használni, amikor az adott pontban több mintát veszel egy iteráción belül). Tervezd meg előre, hogy mit szeretnél, és aszerint válassz (a GPU-n nem éri meg eloszlásonként egynél több mintát venni). Ezt a fogalmat egymástól függetlenül vezette be David Immel és James Kajiya az 1986-os SIGGRAPH-on (igen, már akkor is volt). Ez több mint húsz év a Fred E. Nicodemus által bevezetett BRDF fogalomhoz képest (ne felejtsük el, hogy a 60-as 70-es években még a hadsereg megrendelésére dolgozták ki a később 3D grafikában használt technikákat).
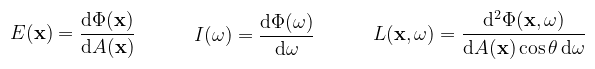
A könyv az egyes differenciálokra mértékként hivatkozik (pl. solid angle measure), de ezt azért teszi, hogy megkülönböztesse a későbbi sűrűségektől (pl. solid angle density). Kicsit pongyola, mert egyébként tényleg mértékként használja ezeket. Ahogy írtam a radianciát kétféleképpen értelmezzük az ω iránytól függően: beérkező (Li(x, ωi)), illetve kimenő (Lo(x, ωo)). Utóbbit szeretnénk meghatározni, i.e. egy ωo irányból milyennek látszódik egy adott anyagtulajdonságú felület, amikor egy ωi irányból érkező fénysugár interaktál vele. 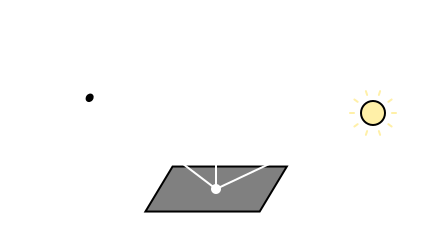
(megj.: az ábráról nem egyértelmű, de természetesen mindegyik vektor normalizált) A felület által visszatükrözött fény intenzitását az irradiancia határozza meg: ha a felület valamilyen szöget zár be a fényforráshoz képest, akkor a vetített terület jobban szétcsúszik rajta, azaz kevésbé látszik fényesnek. Valamilyen x felületi pontba az ωi irány körüli dωi-vel jelölt végtelenül kicsi térszögből érkező radiancia ((Li(x, ωi)) határozza meg a differenciális irradiancát a képletek egyszerű átrendezésével: 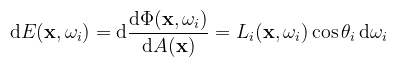
(megj.: vegyük észre, hogy a differenciális irradiancia az iránytól is függ, nem véletlenül!) Nicodemus azt mutatta meg a dolgozatában, hogy a differenciális irradiancia és a kimenő iránybeli (szenzor által érzékelt) radiancia egyenesen arányos, és ezt az arányt nevezi BRDF-nek (bidirectional reflectance distribution function). 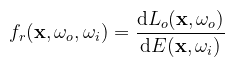
A műszert, amivel ezt a mennyiséget mérik, gonioreflektométernek hívják (lehetetlen megjegyezni); pongyolán úgy működik, hogy az anyagdarab körül a fényforrás és a szenzor egy félgömböt bejárva megméri az összes lehetséges radiancia értéket (és egyéb dolgokat), amiből egy háromdimenziós vektormező áll elő. A MERL adatbázisban több ilyen mérés is megtalálható, ezek megtekinthetőek az azóta open-source BRDF Explorer-rel. Az anyagtulajdonság leírását ismerve további átrendezéssel, illetve integrálással az alábbi egyenlethez jutunk: 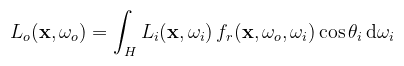
Ahol H az x pont körüli félgömb. Az egyenlet szerint a kimenő iránybeli radiancia a félgömbön belüli összes irányból érkező differenciális irradiancia* folytonos összege (az integráljel egy stilizált S betű). Logikusan ezért radiance equation a neve. (* súlyozva a BRDF értékével; ha nem mondok mást, akkor fr = ρ/π a Lambert BRDF) Valami azonban még hiányzik: honnan származik a beérkező radiancia? Más szavakkal: hogyan kell módosítani az egyenletet, hogy a fényforrás által kisugárzott radiancia (emitted radiance) is benne legyen? Bármily meglepő úgy, hogy egyszerűen hozzáadjuk: 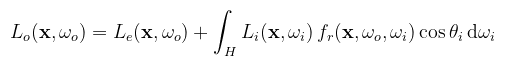
Ami annyit jelent, hogy ha az x pont egy fényforráson van, akkor Le(x, ωo) a kisugárzott radiancia. Ha nem fényforráson van, akkor pedig nulla. Mivel a rekurzivitása által a teljes globális megvilágítást összefoglalja egyetlen formulában, a neve rendering equation. Fontos még megemlíteni, hogy a differenciális térszög helyébe behelyettesíthető a térszög-felszín összefüggés, ami által az integrálást egy tetszőleges felületen is elvégezhetjük (tipikusan fényforráson): 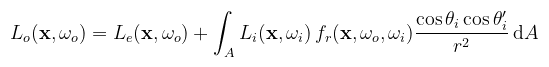
Kétféle mérték szerint is működik tehát az integrálás, lássuk hogyan tudjuk ezt a tudást kamatoztatni. Ez az első konkrét módszer, amihez példakódot is írtam. Arra a kérdésre keresünk választ, hogy mit kell akkor csinálni, amikor többféle stratégia szerint is mintavételezhetnénk:
Helyhiány miatt csak a lényeget rajzoltam meg. A bal oldali ábrán szereplő matt felületet (a BRDF lufi egy félgömb) alapból koszinusz eloszlással mintavételeznénk, de akkor rengeteg minta nem találja el a fényforrást. Célszerűbb ezért a fényforrás szerint mintavételezni. A jobb oldali ábrán viszont egy tükröző felület van (a BRDF lufi keskeny), itt meg a BRDF-et éri meg inkább mintavételezni (szélsőséges eset a tökéletes tükröződés, amikor pontosan egy irány van). Amit Veach megmutatott az az, hogy hogyan lehet ezeket a stratégiákat úgy összekombinálni, hogy a döntéssel igazából ne kelljen foglalkozni. A formális definícióval viszont óvatosan kell bánni, mert különböző irodalmak máshogyan mutatják be. Induljunk ki abból, hogy továbbra is valamilyen f függvény integrálját szeretnénk közelíteni, viszont most M darab mintavételezési stratégiánk van, amikből összesen N mintát húzunk (egy konkrét pi pdf-ből Ni mintát). Ekkor a MIS közelítőt az alábbi módon írhatjuk fel: 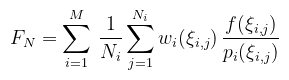
ahol a wi-k súlyfüggvények az alábbi feltételekkel:
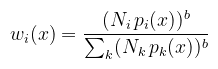
Ami b = 1 esetén balance heuristic, egyébként power heuristic névre hallgat (a gyakorlatban b = 2 jó választás). Ennek a szerepe, hogy azokon a helyeken, ahol egy pdf gyengén teljesít (pl. firefly-t csinál a pixelből), ott a hozzá tartozó értéket lenyomja nullához közelre. Röviden a példakódról: mivel magát az algoritmust akartam tesztelni, a felhasználható objektumok (itt) analitikus felületek (gömb, síkdarab, stb.), amikkel könnyű metszetet találni. Az implementáció a fragment shader-ben található, hasonlóan mint ahogy korábbi cikkekben is csináltam (a különbség igazából csak a véletlenszám generátor). A shader minden pixelre megkeresi a sugár mentén legközelebbi objektummal való metszetet, meghatározza a szükséges adatokat és meghívja a lenti kódot. Ja igen, mert amit az ábrákon bemutattam egyébként explicit light sampling-nak nevezik. Eldönthető, hogy minden fényforrást beleveszünk-e a számolásba vagy véletlenszerűen választunk egyet (akár azt is importance sampling-gal). Mindkettőt kipróbáltam, de ennél a példánál az előbbit alkalmazom. Anélkül, hogy az egyes részimplementációkba belemennék, csak a MIS-re koncentrálva mutatom meg a kód releváns részét. Ha valakit ez nagyon zavar, akkor ahogy mondtam, gondoljon a Lambert BRDF-re (ρ/π, a hozzá való pdf pedig cos(θ)/π). Kétféle mintavételezési stratégia van, mindkettő szerint csak 1-1 mintát veszek (viszont öt darab fényforrásra, szóval összesen hat mintavételezés van). CODE
vec3 SampleLightsExplicit(vec3 p, vec3 n, vec3 wo, SceneObject obj)
{
vec4 sample, fr;
vec3 sum = vec3(0.0);
vec2 xi;
float weight;
// #1 a fényforrások mintavételezése
for (int k = 0; k < numLights; ++k) {
SceneObject light = objects.data[k];
xi = Random2();
// mintavételezés a k-adik fényforráson (xyz = irány, w = pdf)
sample = ConeSampleSphere(p, light.center, light.radius, xi);
// ha akarunk árnyékokat, akkor tesztelni kell, hogy takarásban van-e
float vis = Visibility(p, sample.xyz, k);
float ndotl = vis * max(0.0, dot(sample.xyz, n));
// BRDF kiértékelése (xyz = szín, w = pdf)
fr = EvaluateBSDF(obj.bsdf, sample.xyz, wo, n);
if (sample.w > EPSILON) {
weight = PowerHeuristic(1, sample.w, 1, fr.w);
sum += (light.rgb * fr.xyz * ndotl * weight) / sample.w;
}
}
xi = Random2();
// #2 a BRDF mintavételezése (egyben ki is értékeli az első paraméterbe)
sample = SampleEvaluateBSDFImportance(fr.xyz, obj.bsdf, wo, n, xi);
if (sample.w < EPSILON)
return sum;
// mindig tesztelni kell, hogy eltalál-e fényforrást
int index = FindIntersection(p, sample.xyz);
if (index < numLights) {
SceneObject light = objects.data[index];
// itt külön kell kiszámolni a pdf-et
fr.w = PDF_ConeSampledSphere(p, light.center, light.radius);
weight = PowerHeuristic(1, sample.w, 1, fr.w);
sum += (light.rgb * fr.xyz * weight);
}
return sum;
}
Rengeteg kérdés merül fel, pedig igyekeztem egyszerűsíteni a kódot. Azt kell észben tartani, hogy ez a GPU-n fut, tehát ha meg tudok spórolni valamit, azt megspórolom. A fények mintavételezésénél például nem érdekel, hogy mi van abban az irányban, ezért a Visibility() egy korán termináló ciklus. A BRDF mintavételezésekor viszont tudnom kell, hogy fényforrást talált-e el és melyiket. Az is látszik, hogy érdemes mindenféle kombinációt implementálni: olyat ami mintavételez, kiértékel vagy mindkettőt megcsinálja. A pdf-eket célszerű külön függvényként is elérhetővé tenni. Másfélmillió forintos kérdés, hogy a fényeknél miért van n·l illetve pdf-el osztás, a BRDF-nél meg miért nincs. Azért, mert a SampleEvaluateBSDFImportance(), ahogy a nevében is benne van kiértékeli a BRDF-et a megfelelő importance sampling stratégiát is figyelembe véve (ezzel szintén időt spórol). Na de lássuk, hogy miben segít ez (mondjuk 4 iterációra): 
(megj.: Veach szerint teljesen mindegy, hogy a mintákat hogyan osztod szét, amíg a súlyfüggvényt jól választod meg) Amint a képen látható (klikk), valóban anélkül kombinálja össze az egyes stratégiák előnyeit, hogy bármit is tudna a jelenetről. A fény mintavételezése például erős kis fényforrások esetén, de gyenge a nagyoknál. Hasonlóan a BRDF mintavételezése nagy fényforrásoknál erős, a kicsiket viszont el se találja. Sőt, mivel csak a BRDF lufin belül mintavételez, a köztes helyeken fekete. Még egyszer, ezeket a képeket direkt kevés iterációval csináltam (összesen 24 minta). Gondolom nem kell mondani, hogy normális felbontásban és sok iterációra is teljesen valósidejű. Jöjjön most egy kis kitérő arról, hogy hogyan kell ilyen tükröződéseket csinálni (és miért BSDF szerepel a kódban). Tulajdonképpen volt már erről szó, de akkor helytelenül Cook-Torrance modellnek írtam (utóbbi π-vel oszt le 4 helyett). Mentségemre az akkori irodalmak is összekeverték. Az egyébként valóban igaz, hogy a Cook-Torrance BRDF egy általánosabb fejlesztés (1982, hol máshol, mint a Lucasfilm-nél), merthogy az eredeti elméletet 1967-ben publikálta K. E. Torrance és E. M. Sparrow. Nosztalgiából érdemes elolvasni, hogy akkor hogyan jutottak el a modellhez. Szerintem nyugodtan mondhatjuk, hogy kiállta az idő próbáját.
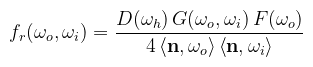
Ahol D a mikrofelület normálvektorok eloszlását jellemzi, G az ún. masking-shadowing function (ez majd érdekes lesz), F pedig a Fresnel együttható. Az első fontos dolog, amit megemlítenék, hogy bár D és G megválaszthatóak, a közelítések konzisztensek kell legyenek. Például mivel maradok a GGX függvénynél, ahhoz a Smith-GGX közelítést kell használnom G-re (ne tudjátok meg mennyit téptem a hajam, mire rájöttem). Az alábbi képletek közelítések; az eredeti formulák megtalálhatóak az irodalomjegyzékben (de ember legyen a talpán, aki megérti). α mindig a rücskösséget jelenti (nem szabad varacskolni mint raszterizációnál, mert nem fogsz rájönni, hogy mitől rossz): 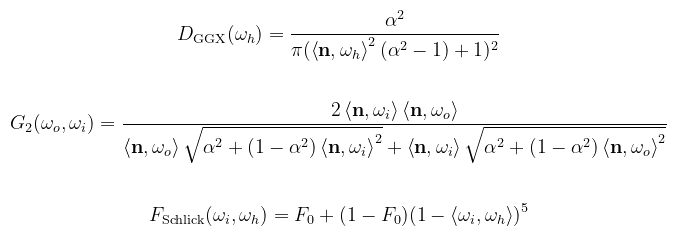
(megj.: G2-nek helyhiány miatt nem írtam ki a nevét; egyébként height-correlated Smith-GGX) Ezt így ne kódoljátok le. Persze szükség lesz rá, de a képletből nem látszik, hogy miként kell a GPU-ra optimalizálni. Fontosabb kérdés, hogy hogyan lehet mintavételezni. Először is nézzük meg, hogy a három részfüggvény közül melyik a domináns: 
(megj.: G2-ben az a sötétebb rész a képletből következik, a BRDF nevezője ejti ki) Ha nem gondolkozunk sokat, akkor az látható, hogy a D függvény határozza meg a BRDF lufi alakját. Az ilyen függvények kollektív elnevezése NDF (normal distribution function), és definíció szerint azt mondja meg, hogy mennyire "valószínű", hogy a mikrofelület a paraméterben megkapott irányba néz (i.e. egy Dirac delta eloszlás integrálja a mikrofelszínen). Itt most egy kicsit makizni fogok, de az NDF-nek van egy olyan tulajdonsága, hogy a mikrofelszín vetített területe a makrofelület normálvektora mentén meg kell egyezzen a makrofelület területével (konvenció szerint 1 m2). Formálisan: 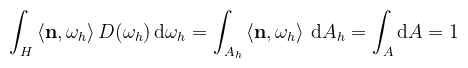
Ahol dAh azoknak a mikrofelületeknek az összterülete, amiknek a normálvektora a dωh térszögbe esik (makizás, mondom). A levezetés megtalálható Eric Heitz publikációjában (erre G2 kapcsán majd még visszatérek). A lényeg, hogy a felírt integrandus teljesíti a pdf követelményeit. Sőt, mivel izotróp (forgatás hatására nem változik a kinézete), θ és φ megint függetlenek. A skaláris szorzat írható cos θh-ként is, tehát akkor a Kőbe Vésett Egyenlet™ alapján a GGX függvényre: 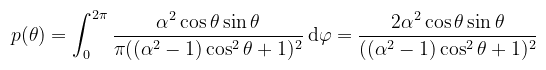
Naja, hát ez nem valami szép; mázlink van viszont, mert u = cos2 x helyettesítésssel: 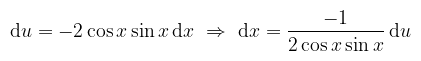
Ez tök jó, mert kiejti a számlálót. Ne felejtsük el viszont, hogy az integrálás tartományát is le kell követni: 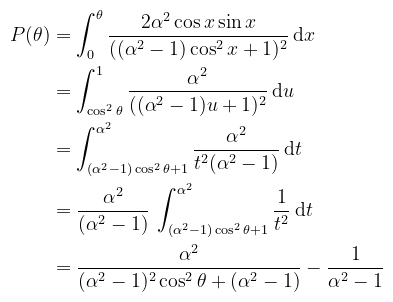
Baromi könnyű elszámolni, különösen az előjelváltásoknál. Láthatóan kellett egy második helyettesítés is; a kettőt össze lehetett volna vonni, mindegy (ne csak én számoljak). A mintavételezéshez ezt még ugye invertálni kell; a hajtépés elkerülése érdekében csak az eredményt írom le: 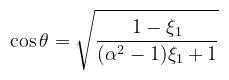
Egyszerű algebrai manipulációkat kellett csak alkalmazni (viszont hosszú leírni). Lássuk akkor, hogy kódban hogyan fest: CODE
vec3 GGXSampleHemisphere(float xi1, float xi2, float roughness)
{
float a2 = roughness * roughness;
float phi = TWO_PI * xi2;
float costheta = sqrt((1.0 - xi1) / (a2 - 1) * xi1 + 1.0);
float sintheta = sqrt(1.0 - costheta * costheta);
vec3 h;
h.x = sintheta * cos(phi);
h.y = sintheta * sin(phi);
h.z = costheta;
return h;
}
És most ismét álljunk meg. Mire kapunk itt mintát? A változónév árulkodik: a félvektorra. Ezt nagyon nem szabad elfelejteni, mert szintén nem fogsz rájönni, hogy miért nem úgy néz ki, ahogy kellene. A bejövő irányt tehát a félvektorból és a kimenő vektorból kell visszaszámolni. Na de várjunk...ha az irányok különböznek, akkor a sűrűségek is! Ha mondjuk θh most a félvektor és a kimenő vektor közötti szög, akkor θi = 2θh (a félvektor definíciójából). Ismét előkapva a függvénytáblákat: 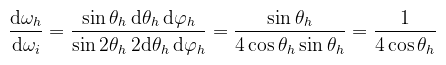
Az irodalmak szerint ez a vektorra való tükrözés Jacobi determinánsa (elhisszük). CODE
vec4 GetReflectedDirectionAndPDF(vec3 wh, vec3 wo, float pdf)
{
vec4 wi_pdf;
float vdoth = dot(wo, wh);
wi_pdf.xyz = 2.0 * vdoth * wh - wo;
wi_pdf.w = pdf / (4.0 * vdoth);
return wi_pdf;
}
Örülünk, Vincent? Nos...igen is, meg nem is. Bár találtunk egy mintavételezési stratégiát, a szépséghiba csak annyi, hogy nem ez a legjobb. Teljesen megfeledkeztünk ugyanis a masking-shadowing függvényről. A mikrofelületek takarásban lehetnek akár a fény (shadowing) akár a kamera szemszögéből (masking). Utóbbi az érdekes: hatékonyabb a közelítés, ha eleve csak a látható mikrofelületek szerint mintavételezünk. Itt térnék vissza Heitz dolgozatához. Először egy kis fejtágítás: a fenti G2 az ún. height-correlated masking-shadowing function, ami figyelembe veszi, hogy egy adott mikrofelület magassága korrelációban van a környezetében levőkkel. A Smith mikrofelszín profil ezzel eredetileg nem foglalkozik, hanem egy G1-el jelölt függvénnyel jellemzi a mikrofelületek adott irányból való láthatóságát. A GGX eloszlásra ez 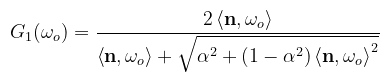
(megj.: vigyázat, nem írtam el, az ott tényleg plusz; speciel két ilyen szorzata a korrelálatlan G2) Heitz megmutatja, hogy ezzel az egyirányú G1 függvénnyel beszorozva adható egy Dωo-val jelölt függvény, ami immár a kimenő irányból látható mikrofelületek normálvektorainak sűrűségfüggvénye: 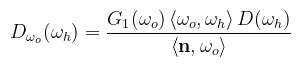
És ez az a pont, ahol a dolgozat kiegészítő része átmegy nehezen érthetőből kénköves pokolba, ugyanis az eloszlásfüggvényre nincs zárt formula (GGX esetén, ahogy ők paraméterezik). Szerencsére 2018-ban a szerző adott egy jóval egyszerűbb megoldást. Az alapötlet az, hogy α = 1 esetén a GGX lufiból egyenletes eloszlású félgömb lesz (helyettesíts be). Heitz azt mondja, hogy mivel a GGX függvény a nyújtásra nézve invariáns, a számolás elvégezhető úgy, hogy a bejövő vektort megnyújtjuk α-val. Ezáltal dolgozhatunk a félgömbbel, majd az eredményt visszanyomjuk az eredeti lufiba. CODE
vec3 GGXSampleHemisphereVisible(float xi1, float xi2, vec3 wo, float roughness)
{
// kinyújtjuk a félgömbbe (tfh. wo a kanonikus bázisban van)
vec3 wo_s = normalize(vec3(wo.x * roughness, wo.y * roughness, wo.z));
// generálunk a kimenő vektor körül egy ortonormált bázist
vec3 up = ((abs(wo_s.z) < 0.999) ? vec3(0, 0, 1) : vec3(1, 0, 0));
vec3 tangent = normalize(cross(up, wo_s));
vec3 bitangent = cross(wo_s, tangent);
// a vetített korongok paraméterezése
float r = sqrt(xi1);
float phi = TWO_PI * xi2;
float t1 = r * cos(phi);
float t2 = r * sin(phi);
float s = 0.5 * (1.0 + wo_s.z);
t2 = (1.0 - s) * sqrt(1.0 - t1 * t1) + s * t2;
// visszavetítés a félgömbre
float vh = sqrt(max(0.0, 1.0 - t1 * t1 - t2 * t2));
vec3 h = t1 * tangent + t2 * bitangent + vh * wo_s;
// visszagyömöszölés a lufiba
h = normalize(vec3(h.x * roughness, h.y * roughness, max(0.0, h.z)));
return h;
}
Néhányszor átolvasva a dolgozatot nagyjából megérthető, hogy mi történik: a félgömb alapkorongját két félkorongra bontja (az egyik az alapsíkban, a másik a kimenő vektor síkjában). A mintavételezés a félkorongoknak a kimenő irányvektor menti vetületén történik (ld. a dolgozatot ábrákhoz). Végül nézzük meg, hogy ezzel a mintavételezéssel hogyan egyszerűsödik a tükröződési egyenlet Monte Carlo közelítése: 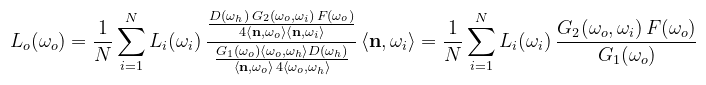
Kiesett D is és a koszinuszok is, ami lényegesen csökkenti a szórást (egy mezei koszinusz mintavételezéshez képest). Pudingpróba 16 minta/pixelre: 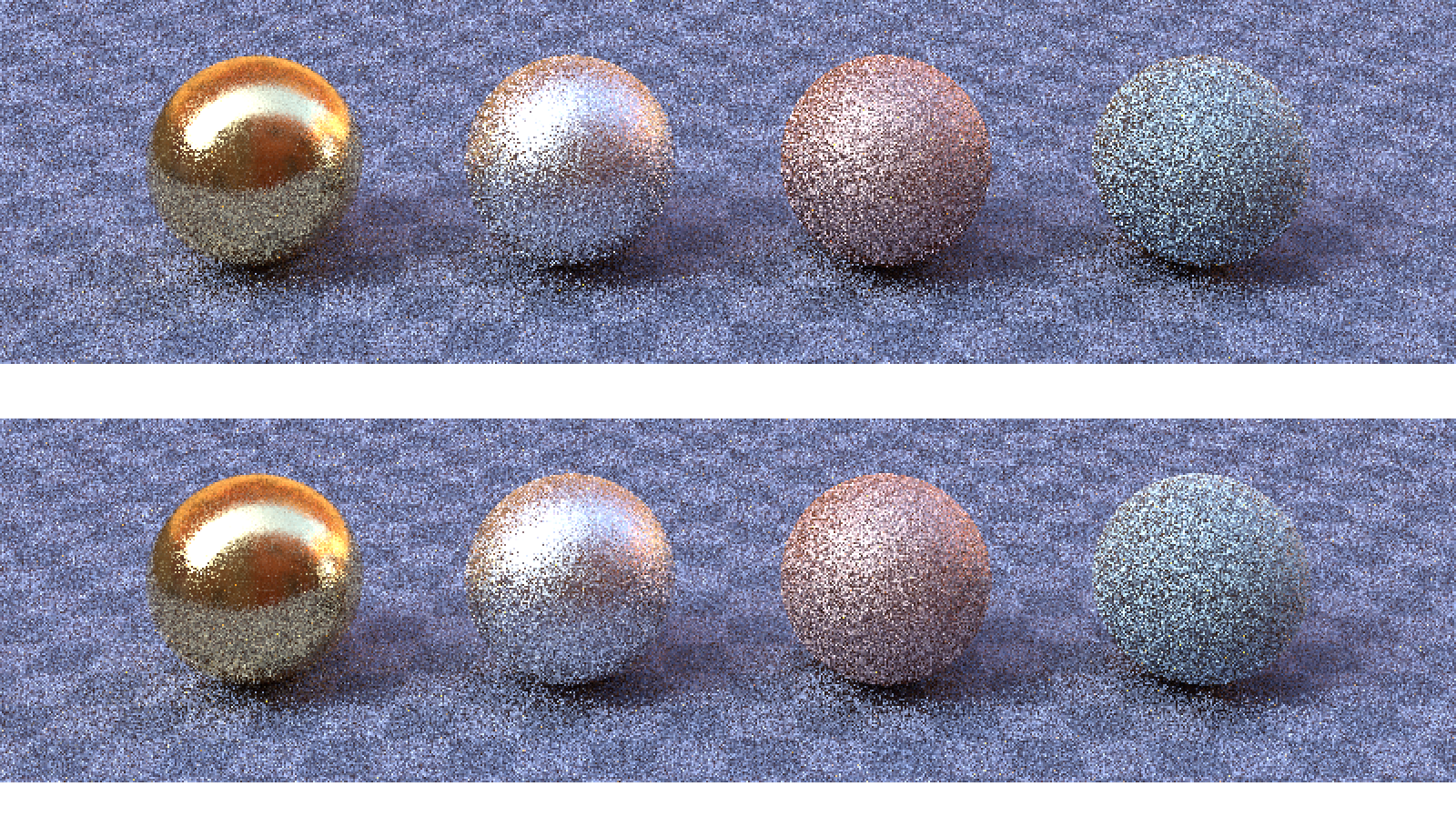
(megj.: mindegyik gömb fém, a rücskösségek balról jobbra: 0.05, 0.25, 0.5, 0.75) Az látszik, hogy a látható normálvektorokat figyelembe vevő mintavételezés inkább az erősen rücskös felületeknél segít, illetve az objektumok széleinél (ahol éles szög alól látszanak a mikrofelületek). Hozzátenném azért, hogy itt egyéb dolgok is működnek a háttérben, amik csökkentik a szórást, de azok nélkül ilyen kevés iterációra értelmezhetetlen lenne a kép. Ez elsőre nem nyilvánvaló, merthogy a Fresnel-egyenletek szerint a radiancia egy része tükröződik (BRDF félgömb), a másik része megtörik és áthalad a felületen (BTDF félgömb). Path tracing-ben nem akarunk egyszerre két irányba pattogni. Hogyan lehetne akkor ezt megoldani? Nézzük meg mit csináltunk raszterizációnál, hátha ad ötletet:
CODE
vec3 EvaluateDielectric(vec3 wo, vec3 n, float eta)
{
float F = F_Schlick(eta, dot(wo, n));
vec3 wi_r = reflect(-wo, n);
vec3 wi_t = refract(-wo, n, eta);
vec3 reflection = texture(samp, wi_r).rgb;
vec3 transmission = texture(samp, wi_t).rgb;
return reflection * F + transmission * (1.0 - F);
}
(megj.: η = η1 / η2 a két közeg törésmutatóinak hányadosa) Hmm... F és 1 - F? Ezek szerint a Fresnel együttható alapján eldönthető, hogy merre menjünk tovább (és emiatt része lesz a pdf-nek). A BTDF-et viszont még nem tudjuk, ehhez megint a könyvet kell elővenni: 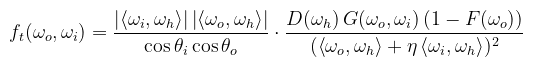
(megj.: vigyázat, a félvektor itt ωh = ωo + η ωi) Ez még rondább képlet, mint a tükröződés...reménykedjünk, hogy a pdf megint kiejti a dolgokat. Naná, ha megnézzük a könyv levezetését, akkor nyilvánvaló, hogy ki fogja ejteni, ugyanis a BTDF-et a fénytörés Jacobi determinánsával definiálta: 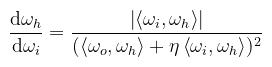
Na most az a helyzet, hogy erre egyik irodalom sem mutat normális bizonyítást. A legközelebbi, amit találtam Jos Stam dolgozata (Appendix B), de amellett, hogy kissé obfuszkált, az eredmény sem egészen az, amit vártam. Mindegy, lássuk mihez lehet ezzel kezdeni. Természetesen még mindig a látható mikronormálokat mintavételezzük, tehát a Heitz-féle Dωo-ból kapjuk a félvektort. Viszont ahogy a bekezdés elején mondtam, a Fresnel együttható szerint kell eldönteni, hogy tükröződés vagy fénytörés történt-e: CODE
vec4 SampleMicrofacetDielectric(vec3 wo, vec3 n, float roughness, float eta, float xi1, float xi2)
{
vec4 wi_pdf;
vec4 wh_pdf;
// bentről is jöhet a sugár; mindig a felület külső oldalán számolunk
bool entering = (dot(wo, n) > 0.0);
if (entering) {
wh_pdf.xyz = GGXSampleHemisphereVisible(n, wo, roughness, xi1, xi2);
wh_pdf.w = PDF_GGXVisible(n, wo, wh_pdf.xyz, roughness);
} else {
wh_pdf.xyz = GGXSampleHemisphereVisible(n, -wo, roughness, xi1, xi2);
wh_pdf.w = PDF_GGXVisible(n, -wo, wh_pdf.xyz, roughness);
}
float F = F_Schlick(eta, dot(wo, n));
float u = Random1();
bool refracted = false;
if (entering) {
wi_pdf.xyz = refract(-wo, n, eta);
} else {
// ha bentről jött a sugár, akkor a Fresnel eh. is megfordul
wi_pdf.xyz = refract(-wo, -n, 1.0 / eta);
F = F_Schlick(eta, dot(wi_pdf.xyz, n));
}
// itt kerül bele a pdf-be a Fresnel eh.
if (u < F) {
// tükröződés
wi_pdf = vec4(reflect(-wo, n), F);
} else {
// fénytörés
wi_pdf.w = (1.0 - F);
// TODO: teljes belső visszaverődés kezelése
refracted = true;
}
// pdf szorzása a Jacobi-val
if (refracted) {
float sqrtdenom = dot(wo, h) + eta * dot(wi_pdf.xyz, h);
wi_pdf.w = wh_pdf.w * abs(dot(wi_pdf.xyz, h)) / (sqrtdenom * sqrtdenom);
} else {
wi_pdf.w = wh_pdf.w / (4.0 * dot(wo, h));
}
return wi_pdf;
}
Ez egy összevont kód, a tényleges implementáció egyéb okokból szét van bontva. A teljes belső visszaverődést (total internal reflection) itt nem kezeltem le; ez olyankor történik, amikor a bejövő sugár az ún. kritikus szögben találja el a felületet (a nagyobb törésmutatójú közegből a kisebb felé) és nem képes áthatolni rajta. Ezt a refract függvény úgy jelzi, hogy nullvektort ad vissza. Az implementációk ilyenkor többnyire terminálják a path-ot. Egy ehhez kapcsolódó fontos dolog, hogy a BTDF ezek szerint nem szimmetrikus: amikor a kamera irányából számoljuk a fénytörést, akkor az eredményt be kell még szorozni η2-el (ld. a könyv vonatkozó részét). A referencia ezt mikrofelületnél valamiért nem teszi meg (úgyhogy értelemszerűen kihagytam). Ha ismét összerakjuk az egyes képleteket, akkor kiértékeléskor a BTDF az alábbira egyszerűsödik (nem fért ki, de elhiszitek): 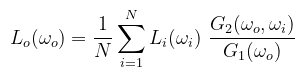
Igen, tényleg ennyi. Ha kicsit belegondolunk annyira nem meglepő: mivel a Fresnel együtthatót belevettük a mintavételezésbe (és ezáltal a pdf-be), logikus, hogy eltűnt a kiértékelésből. A BTDF pedig a megfelelő vektorok megfordításával teljesen hasonló, mint a BRDF (kivéve az említett asszimetriát). A kettőt együtt BSDF-nek (bidirectional scattering distribution function) nevezzük. Az alábbi képet hagytam végigkonvergálni (1024 iteráció, néhány másodperc): 
(megj.: üveggömbök, azaz η = 1.5; a rücskösségek balról jobbra: 0.005, 0.05, 0.1, 0.25) Színes üvegeket eddig nem sikerült értelmesen megjelenítenem (és ez nem csak nálam probléma). A tesztjelenetek is inkább ködösítő közegekkel oldják meg, maga az üveg színtelen. Miközben mutogattam ezt a képet felmerült az a kérdés, hogy mi az ott a gömbök alján: a kétszeres fénytörés lencsehatást vált ki, szóval az a háttér (illetve az environment map amit éppen beraktam). Gondolom világos, hogy fénytöréshez már tényleges path tracing-re van szükség, szóval itt is megelőlegeztem néhány dolgot. Ebben a bekezdésben arra szeretnék fókuszálni, hogy mi is ez a "standard" megközelítés fotorealiszikus képek előállítására. Röviden mondhatnám azt, hogy "amit könnyű leimplementálni", ami egyébként igaz, amennyiben a fenti speciális BSDF-eket figyelmen kívül hagyod. De akkor kénytelen vagy arra hagyatkozni, amit már ismersz (pl. a sokat emlegetett Lambert BRDF). Egyébként nem tévednél (csak vizuálisan egyhangú lenne a kép).
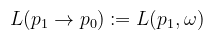
Hasonlóan, ha adottak az ωi és ωo irányok, akkor a p2, p1, p0 pontsorozatra hasonlóan jelölhető a BSDF, illetve a térszögből felszínbe való konverzió Jacobi determinánsa, amit az irodalmak egyszerűen csak G-vel jelölnek (geometry term). Ezt külön nem írom le, mert már láttuk (a két koszinusz szorzata osztva a távolság négyzetével és beszorozva egy láthatósági függvénnyel). A megjelenítési egyenlet (vagy most már akkor inkább fényterjedési egyenlet) a következőképpen írható fel: 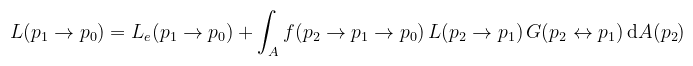
A félreértések elkerülése végett mégegyszer: ez a megjelenítési egyenletnek egy másfajta felírása, amiben az irányok ki vannak cserélve erre az ún. "hárompontos alakra". A rekurziv jellegét természetesen megőrizte: az integrandusban szereplő radiancia helyén lehet "pumpálni". Kezdjük el akkor az egyenlet kifejtését: vegyünk egy negyedik pontot (p3), és az arra felírt teljesen hasonló egyenlet jobb oldalát helyettesítsük be L(p2 → p1) helyére (katt a nagyításhoz): 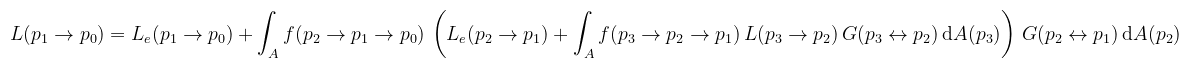
Gondolom nem kell mondani, hogy ezt milyen melós dolog újra meg újra elvégezni (egyre hosszabb formulát kapva), úgyhogy az algebrai manipulációkat rátok bízva a kompakt alakot adom meg: 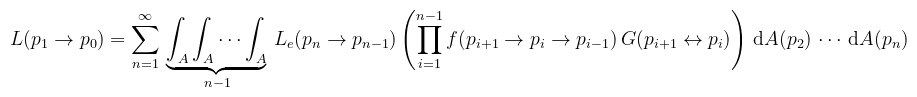
Megjegyzendő, hogy n itt az útvonal hossza. Lehetne kötekedni, hogy a formula kicsit csal, de ha nem integrálunk (n = 1), akkor értelemszerűen a mértéket sem kell odaképzelni. Amikor path tracing-ről beszélünk, akkor p0 mindig a filmen/lencsén értendő, pn pedig egy fényforráson. Az útintegrált (jobb fordítás híján) az ún. útvonaltéren (path space, Ω) értelmezzük, ami az összes n hosszú útvonalak halmazainak úniója (tehát minden lehetséges véges útvonal). Vegyük észre, hogy ebben már nincs rekurzivitás. A p = p0, ..., pn alakú útvonalakra definiáljuk az alábbi mértéket (ún. area-product measure, i.e. területek szorzata): 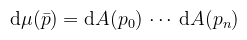
(megj.: miért differenciál: azért mert magát a mértéket halmazokra lehet definiálni) És ami maradt az akkor ezek szerint az integrandus, vagy becsületes nevén measurement contribution function, szintén n hosszú útvonalanként értelmezve, azaz a szumma lecserélődik integrálra, és az alábbi egyenletet nevezzük útintegrál megfogalmazásnak: 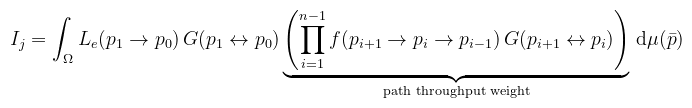
(megj.: Ij a j-edik pixelre kapott mérés; kicsit önkényesen definiáltam, de ugyanez az irodalmakról is elmondható) Ami tehát az említett absztrakt útvonaltéren vett integrál, amiben maguk az útvonalak tekinthetőek pontoknak. Több előnye is van ennek a felírásnak, amit a haladó algoritmusok ki is használnak (pl. az útvonalakat lehet mintavételezni). Részletesebben ld. a SIGGRAPH prezentációját. Most egyelőre elég lesz az, hogy a Monte Carlo közelítését átírjuk shader-be. Az implementáció előtt nézzünk képeket (256 iteráció, legfeljebb 15 hosszú útvonalak): 
(megj.: a fenti útintegrál alak Monte Carlo közelítése a középső kép, tehát a naiv path tracing) Az útvonalakat az ún. local path sampling nevű módszerrel állítom elő, a kamerából kiindulva. Az útvonal (mostantól path) következő pontja az aktuálisan eltalált felület BSDF-jéből választott irány mentén való következő metszéspont. A "naiv" szó itt arra utal, hogy ilyen módon pattogtatva a sugarat reménykedek, hogy eltalálja a fényforrást (implicit path). Ne zavarjon meg az elnevezés, mert egyébként minden ismert importance sampling stratégiát alkalmazok! A next event estimation nevű technika alatt annyit kell érteni, hogy az útintegrál alakba minden pattogásnál belevesszük a közvetlen megvilágítást is (i.e. meg kell hívni a SampleLightsExplicit() függvényt). Logikusan ezért szokták úgy is mondani, hogy path tracing with explicit light sampling, de szerintem ez egy kicsit félrevezető elnevezés: tévesen lehet úgy értelmezni, mintha az első két képet összeadnám (nem!). Ellenben érdemes összevetni, hogy milyen röhejes mértékben csökkenti le a szórást! Ez akkor látszik jól igazán, amikor a fényforrás "kicsi". Felmerül viszont egy kérdés: mégis meddig érdemes pattogtatni a sugarat (szintén naiv dolog lenne azt feltételezni, hogy majd csak kiszökik egyszer a jelenetből)? Az a nagy helyzet ugyanis, hogy ha fix számú pattogást engedek meg, az torzítja a közelítést (viszont elég sok iterációval kompenzálható). Erre a Russian roulette nevű technika ad megoldást, ami egy adott pattogásszám után véletlenszerűen terminálja a path-ot. Természetesen ezen orosz rulettre is alkalmazható importance sampling: ha a pattogások által összegyűjtött indirekt megvilágítás (throughput) nem növekszik lényegesen (i.e. egy véletlenszerű értéknél kisebb), akkor a path-ot korán terminálom (ld. Veach dolgozatát a formális levezetéshez). Az alábbi kód a next event estimation-nel és a Russian roulette-tel kiegészített TraceScene() függvény (szintén zanzásítva): CODE
vec3 TraceScene(vec3 raystart, vec3 raydir)
{
vec4 sample1;
vec3 color = vec3(0.0);
vec3 throughput = vec3(1.0); // path throughput weight (β)
vec3 outray = raydir;
vec3 n, p = raystart;
vec3 indirect;
vec2 xi;
bool refracted = false;
for (int bounce = 0; bounce < MAX_BOUNCES; ++bounce) {
int index = FindIntersection(p, n, p, outray);
if (index >= numObjects)
break;
SceneObject obj = objects.data[index];
uint shapetype = obj.params.x;
if ((shapetype & SHAPE_EMITTER) == SHAPE_EMITTER) {
// implicit path, nem szabad kétszer számolni a fényt
if (bounce == 0 || refracted)
color += throughput * obj.radiance;
break;
}
// közvetlen megvilágítás (next event estimation)
color += throughput * SampleLightsExplicit(p, n, -outray, obj);
xi = Random2();
// BSDF és geometry term kiértékelése, új irány választása
refracted = SampleEvaluateBSDFImportance(sample1, indirect, obj.bsdf, -outray, n, xi);
if (sample1.w < EPSILON || IsBlack(indirect))
break;
throughput *= indirect;
outray = sample1.xyz;
// Russian roulette
if (bounce > 3) {
float q = max(throughput.x, max(throughput.y, throughput.z));
// ha nem növekszik érdemben β, akkor termináljuk a path-ot
if (q < Random1())
break;
// a pdf-el mindig le kell osztani, ez sem kivétel
throughput /= q;
}
}
return color;
}
Ebben a kódban a fényforrásokat és az objektumokat is ugyanazzal a struktúrával reprezentálom, a fényeket külön megjelölve (és akkor a BSDF alapszíne a radiancia). Ez shader-ek esetén mindig kényelmi ok: elég egy buffert megadni, ami (ha a GPU is úgy gondolja) akár egyben befér a cache-be. A fényforrások a buffer elején vannak, szintén kényelmi okokból. Arra érdemes odafigyelni next event estimation esetén, hogy ha a path mégiscsak eltalálja a fényforrást, akkor nem szabad hozzáadni a radianciát, hiszen a közvetlen megvilágításban már benne van (ún. double dip). Kivétel természetesen az elsődleges sugár és az olyan path-ok, amik fénytörés után jutottak ide (a kausztikákra ugyanis nem lehet közvetlen megvilágítást számolni). Hasonló igaz Dirac delta BSDF-ekre is (tökéletes tükröződés/fénytörés). Az eddigi képeken analitikus felületeket jelenítettem meg, azokkal ugyanis gyorsan lehet metszetet találni, ezáltal lehet a konkrét algoritmusokra koncentrálni. Tetszőleges modell megjelenítése viszont már nem ennyire triviális; legrosszabb esetben az összes modellt alkotó háromszöggel való metszést tesztelni kell, ami nyilvánvalóan nem járható út.

(megj.: a bal oldali kép azt mutatja, hogy a bejárás hol megy mélyebbre a fában; a jobb oldali képen maga a fa látható) A hardverlimitáció az, hogy a GPU-n nincs hagyományos értelemben vett stack: GCN architektúrán work item-enként 4096 temporáris vektorregiszter áll rendelkezésre, és abba minden bele kell férjen (tehát nem csak a BVH bejárása, hanem az összes fenti számolás is). Ez erősen korlátozza, hogy mit lehet cache-elni az osztott illetve a privát memóriában (az anyagokon és fényeken kívül gyakorlatilag semmit). Ennek az eredménye iszonyatos mennyiségű cache miss lesz, mivel az egyes work item-ek folyamatosan konkurens módon nyúlkálnak a globális memóriába (szerencsére csak olvassák). A képen látható elsődleges sugárvetés egyébként még erre a bonyolult modellre is stabil 60 fps; akkor kezd el meredeken zuhanni, amikor elkezdem a konkrét sugárkövetést (az viszont már modellmérettől függetlenül lassú az említett cache miss-ek és a dinamikus elágazások miatt). A kódból a BVH iteratív bejárását mutatom meg (a stack hiánya miatt rekurzió sincs): CODE
bool TraverseBVHClosestHit(out Intersection isect, vec3 raystart, vec3 raydir)
{
uint stack[32];
vec3 invdir = 1.0 / raydir;
vec2 distances;
bvec3 dirisneg = lessThan(invdir, vec3(0.0));
uint nodeID = 0;
int depth = 1;
isect.Distance = FLT_MAX;
while (depth > 0) {
BVHNode node = hierarchy.data[nodeID];
if (RayIntersectAABB(distances, node, raystart, invdir)) {
if (IsLeaf(node)) {
// levélcsúcs, keressük a pontos metszést
Intersection result;
ProcessTriangles(result, node, raystart, raydir);
result.NodeID = nodeID;
if (result.Distance > 0.0 && result.Distance < isect.Distance)
isect = result;
// folytatjuk a keresést
--depth;
nodeID = stack[depth];
} else {
// belső csúcs, a sugárirány alapján eldöntjük, hogy merre kell menni
uint axis = (node.RightOrStart & 0xC0000000) >> 30;
if (dirisneg[axis]) {
// bal gyerekcsúcs a verembe, jobbra folytatjuk
stack[depth] = node.LeftOrCount;
nodeID = node.RightOrStart & (~0xC0000000);
} else {
// jobb gyerekcsúcs a verembe, balra folytatjuk
stack[depth] = node.RightOrStart & (~0xC0000000);
nodeID = node.LeftOrCount;
}
++depth;
}
} else {
// nincs metszet, kivesszük a verem legfelső elemét
--depth;
nodeID = stack[depth];
}
}
return (isect.Distance < FLT_MAX);
}
(megj.: a RightOrStart tagváltozó felső két bitjében tárolom a vágás tengelyét) Bármelyik a témával foglalkozó irodalom hasonló kódot fog mutatni, szóval ezt nem én találtam ki. Kitaláltam viszont mást, ugyanis ez a kód mindig a kamerához legközelebbi metszési pontot adja meg (closest hit), holott például láthatósági teszthez elég lenne csak egy metszetet találni (any hit). Itt jelenik meg az első hasonlóság a hardveres sugárkövetéssel, ott ugyanis külön van closest hit shader és any hit shader (ugyanezen ok miatt). Az any hit esetén viszont van egy bökkenő: bizonyos esetekben újra invokálni szeretném, hogy folytassa a keresést. Ez olyankor jön elő, amikor a jelenetben ún. null-interakciókat is megengedek (pl. átlátszó objektumok vagy ködösítő közegek). Ezeknél ugyanis bár talált metszetet, nem számítanak blokkolónak (átengedik a sugarat). A tesztmodellben ilyen például a függöny. Utóbbi algoritmus tehát állapotfüggő; ezt úgy hidaltam át, hogy a stack-et és az egyéb szükséges dolgokat kiszerveztem egy külön BVHTraverseState nevű struktúrába, amit mindig megkap paraméterben. Maga a bejárás egyébként teljesen hasonló, annyi különbséggel, hogy ha talált metszetet, akkor azonnal visszatér. 
(megj.: a jobb oldali kép validálva van a Mitsuba illetve a pbrt-v3 programokhoz) Érdekességképpen megemlítem, hogy bár a bal oldali kép tisztán fehér diffúz felületekből áll, az előállítása jóval lassabb, mint a tényleges jelenetre ráengedni az algoritmust. Ez elsőre viccesnek hangzik, de gondoljunk bele, hogy a Lambert BRDF-et szinte a teljes félgömbben mintavételezzük (így rengeteg új lehetséges irány van), míg a valódi jelenetben a BRDF-ek "egyszerűek", akár a GGX-el árnyalt bútorzat, vagy a tükrök, ahol csak egyetlen lehetséges irány van (ún. Dirac delta BSDF). Külön nem mutatom be, de a bútorzatnál az Ashikhmin-Shirley BRDF-et használom, ami az energiamegmaradást megtartva modellezi a "lakkozott" (a diffúz felett egy vékony dielektrikus réteg) felületeket. A könyvben ezt FresnelBlend néven lehet megtalálni. A Mitsuba és a Tungsten egy másik modellt használ, de a nemlineáris hatásokat kikapcsolva ugyanazt az eredményt adják. Nem árulják el, de szerintem ez a Weidlich-Wilkie BRDF. Az előre kiszámolt konstansokkal kipróbáltam, és stimmel (viszont általánosságban több munkát igényel). Az említett local path sampling nem tesz megkötést arra, hogy hogyan építed fel a path-ot.
Például nem muszáj a kamerából indulni, lehet a fényforrásból is (akkor viszont bajban leszel, hogy a filmen hova kell leképezni a pontot, azaz nem kimondottan shader barát). De megtehető az is, hogy generálok egy t hosszú subpath-ot a kamerából, egy s hosszú subpath-ot a fényforrásból és a kettőt egy láthatósági teszttel összekötöm.
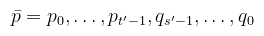
(megj.: a pi pontok tartoznak a camera subpath-hoz, a qi pontok a light subpath-hoz) Ahol t' ≤ t és s' ≤ s. Az említett filmre való nehézkes leképezés miatt az implementációban t ≥ 2, tehát a kamera útvonalán mindig van legalább egy metszési pont (és a kamerával sosem próbálok meg összekötni). A két subpath hosszának variálásával különféle mintavételezési technikákat kapunk, amiknek az összege állítja elő a végleges képet. 
(megj.: az s = 0 képek felelnének meg a naiv path tracing-nek, azaz a BDPT egy általánosítása az eredeti algoritmusnak) Hmm...mintavételezési technikák (súlyozott?) összege...ismerős nem? Ez volt a multiple importance sampling. De vajon mit kell érteni alatta ebben az esetben? Vagy inkább: hogyan kell súlyozni az egyes stratégiákat, hogy a szórás csökkenjen? Mindenki kapaszkodjon meg amibe tud... 
Szóval ahhoz, hogy a MIS súlyt ki lehessen számolni, meg kell határozni az adott path-hoz tartozó összes hipotetikus összekötési stratégia pdf-ét. Bár elkezdtem implementálni, végül feladtam, ugyanis rendkívül bonyolult és csak tovább lassítja a már egyébként is rengeteg számolást végző algoritmust. Amennyiben implementálva lenne, akkor a szórást csökkentené a BDPT képen, de a könyv is megjegyzi, hogy enélkül is jobb eredményt lehet elérni (minőség/sebesség szempontból). Olyan esetekben, ahol a next event estimation túlságosan lelassítja a programot, ott a BDPT egy nyerő alternatíva (eltekintve attól, hogy MIS nélkül nagyobb a variancia). A konyha jelenetre például (pixelenként 4 pattogás, 4 minta): 
Sebesség/szépség arányban a bidirectional path tracing győz, tisztán szépségben a next event estimation, navigálhatóság szempontjából (és sok pattogásra) viszont a naiv path tracing. Feltehető egyébként, hogy én implementáltam szuboptimálisan (előbbit biztos), úgyhogy konkrét mérési adatokat nem mondok (nem is igazán lehet, mert a rajzolás sebessége és a konvergencia gyorsaságának arányát kellene összevetni úgy, hogy egy adott képminőséget elérnek). Nézzünk inkább bele egy kicsit a kódba (legalább abba a részébe ami nincs kikötve). Az első felmerülő kérdés, hogy a két subpath hogyan legyen eltárolva (egyáltalán el kell-e őket tárolni?). Valójában nem kellene, de akkor még úgy álltam neki, hogy a MIS-t is megcsinálom, ahhoz pedig nem árt, ha megvan a teljes path. A globális memória értelemszerűen ki van zárva (eleve amiatt lassú minden). Marad a work group local (shared) és a work item local (private) memória. Előbbit már elméletben elhasználtam az anyagtulajdonságokra, úgyhogy nincs igazán választás. Privát memóriába nagyméretű tömböket tárolni viszont rizikós. Számoljunk: GCN architektúrán work item-enként van 4096 temporáris vektorregiszter, az eltárolandó adatstruktúra kb. 6-7 vektorregisztert tölt ki (ha a GLSL fordító rendesen összepakolja). Annyira nem hangzik rosszul (csak ne felejtsd el, hogy ott van a BVH bejárása is, meg minden egyéb dolog). CODE
struct PathVertex
{
Intersection Interaction;
vec3 Beta; // (sub)path throughput weight
float ForwardPDF;
vec3 OutDir; // ωo
float ReversePDF;
bool IsDelta;
}; // ~7 regiszter
// a SIMD Vector Unit (SVU) regiszter fájlba foglalódnak
PathVertex camerapath[MAX_DEPTH];
PathVertex lightpath[MAX_DEPTH];
Mily szerencse, hogy a függvényen kívül deklarált változók globálisan elérhetőek, de mégis a privát regiszterekbe kerülnek (ez sem volt mindig így...). Első lépésként teljesen hasonlóan, mint fent, elő kell állítani a két subpath-ot (azaz pattogunk egyik felületről a másik felületre, a BSDF alapján pedig választunk új irányt). Mivel a MIS-t kikapcsoltam, nem pazarlok időt arra, hogy például hogyan kell a kamera irányra pdf-et számolni (a könyvben megtalálható). Tegyük fel, hogy a subpath-ok előállítása megtörtént, mi a következő lépés? Fent leírtam: mindent az egyikből megpróbálni összekötni mindennel a másikból (nem, ez nem A három testőr-ből van). CODE
vec3 TraceScene()
{
vec3 color = vec3(0.0);
// subpath-ok generálása, (sub)path throughput weight kiszámolása
int numcamvertices = GenerateCameraSubpath();
int numlightvertices = GenerateLightSubpath();
// mindent megpróbálunk összekötni mindennel (kivéve a kamerával)
for (int s = 0; s <= numlightvertices; ++s) {
int maxt = min(numcamvertices, MAX_DEPTH + 1 - s);
for (int t = 2; t <= maxt; ++t) {
color += ConnectBDPT(s, t);
}
}
return color;
}
Sejthető, hogy a dolog nehéz része az összekötés. És valóban, rengeteg dolgot figyelembe kell venni (pl. s = 0 implicit path, s = 1 esetén mintavételezni kell egy fényforrást, stb.). Hogy valamilyen elképzelés legyen, az általános esetet mutatom meg (itt külön figyelmet érdemelnek azok a helyzetek, amikor nem szabad összekötni, például mert az egyik BSDF Dirac delta): CODE
vec3 ConnectBDPT(int s, int t)
{
vec3 L = vec3(0.0);
vec3 connection;
bvec4 degenerate = bvec4(false);
int remaining = MAX_DEPTH - s - t + 1;
// TODO: s = 0, s = 1 esetek
PathVertex pt = camerapath[t - 1];
PathVertex qs = lightpath[s - 1];
BSDFInfo bsdft = materials.data[pt.Interaction.MaterialID];
BSDFInfo bsdfs = materials.data[qs.Interaction.MaterialID];
vec3 G = GeometryTerm(connection, pt, qs, remaining);
degenerate.x = pt.IsDelta;
degenerate.y = qs.IsDelta;
degenerate.z = (pt.Interaction.NodeID == -1);
degenerate.w = (qs.Interaction.NodeID == -1);
if (any(degenerate)) {
// nem köthető össze
return L;
}
// BSDF-ek kiértékelése
vec3 value1 = BSDF_Vertex(bsdft, connection, pt.OutDir, pt);
vec3 value2 = BSDF_Vertex(bsdfs, qs.OutDir, -connection, qs);
// ld. útintegrál alak
L = qs.Beta * value2 * value1 * pt.Beta * G;
//return L * MISWeight(s, t); // nem impl.
return L;
}
A tényleges kapcsolódási pont keresése a GeometryTerm() függvényben van implementálva. Ez hasonlóan a láthatósági teszthez egy any hit jellegű keresés (áteresztő anyagok miatt), viszont nem engedem tovább kísérletezni, mint amennyit a path hossza megenged. Modellezőknek mondom, hogy az áteresztő objektumok lehetőleg egy rétegből álljanak, hogy a rövidebb path-ok is minél jobban hozzájáruljanak az eredményhez. A MIS hiánya mellett az implementációnak valami problémája van a dielektrikus anyagokkal. Ha belegondolunk ez annyira nem meglepő: hacsak valamelyik subpath nem jutott át sikeresen egy ilyen objektumon, akkor esélytelen normális összeköttetést találni. Ez egyben rámutat a BDPT egy másik igen komoly problémájára: amikor a BSDF szimmetriatulajdonság nem teljesül, akkor azt külön korrigálni kell. Már olyan egyszerű esetekben is megtörténik ez, mint pl. az interpolált normálvektorok. Szintén nem implementáltam le, a megoldáshoz ugyanis kellenek az eredeti (nem interpolált) normálvektorok is, ami csak további helypazarlás. Ezektől eltekintve viszont helyesen működik. Merthogy ami eddig elhangzott az csak a jéghegy csúcsa. Vannak ugyanis olyan esetek, ahol az eddig bemutatott módszerek elhasalnak. Például amikor a fény csak egy keskeny résen keresztül jut be a jelenetbe (majdnem csukott ajtón). Ennek kapcsán szerettem volna még bemutatni a Metropolis light transport nevű algoritmust, de annyira más szemlélet, hogy külön cikket érdemelne.
Sok szempontból nehéz szülés volt ez, és nem csak a téma nehézsége miatt. Retrospektíven több különálló cikkre kellett volna szabdalnom, mert így az esetleges továbbfejlesztés csak ezt fogja hízlalni.
Ha már mozgás: természetesen minden beállítás mellett interaktív az implementáció, viszont ~1300 ms frametime (ez volt a leglassabb, amit kimértem) mellett nem igazán van benne köszönet (és persze amint megmozdulok újraindul a konvergencia). A jellegéből adódóan viszont mozgás közben úgy módosítom, ahogy akarom (beleértve akár a temporal convergence ill. disocclusion detection-t is!). Egyszerűbb jelenetek ugyanakkor egész korrekten eldöcögnek ezek nélkül is. Kód a szokott helyen, néhány videó pedig a másik szokott helyen. Höfö:
Irodalomjegyzék https://mycourses.aalto.fi/course/view.php?id=20635§ion=1 - Advanced Computer Graphics (Jaakko Lehtinen, 2019) https://www.pbr-book.org/ - Physically Based Rendering From Theory To Implementation (Matt Pharr, 2018) https://www.gdcvault.com/play/1024478/PBR-Diffuse-Lighting-for-GGX - PBR Diffuse Lighting for GGX (Respawn, 2017) https://jcgt.org/published/0003/02/03/paper.pdf - Understanding the Masking-Shadowing Function (Eric Heitz, 2014) https://hal.inria.fr/hal-00996995v1/document - Importance Sampling Microfacet-Based BSDFs (Eric Heitz, 2014) https://www.reedbeta.com/blog/hows-the-ndf-really-defined/ - How Is The NDF Really Defined? (Nathan Reed, 2013) https://repository.tudelft.nl/islandora/... - Unbiased physically based rendering on the GPU (Dietger van Antwerpen, 2011) https://research.nvidia.com/publication/... - Understanding the Efficiency of Ray Traversal on GPUs (ACM, 2009) http://web.cs.wpi.edu/~emmanuel/courses/... - Monte Carlo Integration: Basic Concepts (Emmanuel Agu, 2007) https://www.cs.cornell.edu/... - Microfacet Models for Refraction through Rough Surfaces (Bruce Walter, 2007) https://cg.iit.bme.hu/~szirmay/script.pdf - Monte-Carlo Methods in Global Illumination (László Szirmay-Kalos, 1999) http://graphics.stanford.edu/papers/... - Robust Monte Carlo Methods for Light Transport Simulation (Eric Veach, 1997) https://tomacstibor.uni-eszterhazy.hu/tananyagok/Mertekelmelet_eloadas.pdf - Mérték- és integrálelmélet (Tibor Tómács, 2021) https://tomacstibor.uni-eszterhazy.hu/tananyagok/Valoszinusegszamitas.pdf - Valószínűségszámítás (Tibor Tómács, 2021) http://www.ksh.hu/statszemle_archive/2012/... - Monte Carlo módszerek a statisztikában (Dániel Kehl, 2012) https://www.libri.hu/konyv/halmos_paul_r.mertekelmelet-2.html - Mértékelmélet (Paul Halmos R., 2010) |